CASE(计算机辅助软件工程,Computer-Aided SoftwareEngineering),是辅助计算机软件开发的计算机技术,包括在软件开发、维护过程中提供计算机辅助支持以及在软件开发、维护过程中引入工程化方法。CASE工具是一类特殊的软件工具,用于辅助开发、测试、分析和维护另一个计算机程序及相关文档。CASE工具可以分为以下一些类型,即管理工具、编辑工具、配置管理工具、原型工具、方法支持工具、语言处理工具、程序分析工具、测试工具、调试工具、文档工具和再工程工具等,它们可以用来辅助软件开发过程中不同的活动。
上述的CASE工具,同样可以直接应用于GIS软件开发过程中,辅助实施相应的软件开发活动。 此外,还可以针对GIS领域,对CASE工具进行特化,使之更好地支持地理信息系统开发活动。 下面讲述的在GIS开发中,CASE工具另一个方面的应用: 应用配置管理工具实现空间过程支持和空间数据配置管理。
软件配置管理(ConfigurationManagement)是一种标识、组织和控制修改的技术, 可以使软件开发过程由于变更修改引起的混乱降低到最小程度。 目前,配置管理工具已经比较成熟,提供的基本功能包括:
配置标识: 在软件开发过程中,各种相关的文档在不断地变更,在变更过程中每一个时刻的内容都称为一个配置,可以命名配置以实现控制和管理。
版本控制: 版本控制用来管理软件工程过程中所建立起来的配置对象的不同版本。
变更控制: 变更控制通过“检出(Check out)”和“登入(Check in)”机制实现在多人共同开发软件时,不至于因为共同修改同一文件引起混乱。
配置状态报告: 配置状态报告通过系统地记录开发过程,反映开发活动的历史情况。
配置审核: 配置审核的目的是为了证实整个软件生存期中各项产品在技术上和管理上的完整性,并保证所有文档的内容变动不超出当初确定的软件要求范围。
实际上,通过控制不同版本的配置,可以实现整个软件过程的管理,跟踪每份文档的变化,确定文档之间的依赖性。 这些特性,同样可以应用于空间过程和空间数据的管理和控制。
在一个较大规模的GIS应用软件的建立过程中,常常要处理大量的数据,概括地说,具有以下特征:
数据量大;
数据经常变更,比如从遥感图像解译得到的土地利用图以及地籍图;
对一份或多份数据的空间模型运算,可以得到派生的数据,换言之,数据之间通过空间模型产生了依赖性;
空间模型也是在不断变化。
这时,数据变得混乱而难于控制,管理人员无法了解整个项目的进度。 在GIS中引入配置管理的概念,可以管理空间数据和空间模型的多个版本,进而支持空间过程, 辅助GIS应用系统的建立。
过程(Process)的概念目前被应用于不同的领域, 指被“元程序(Meta-program)”控制的计算机程序以及数据交换复杂的序列。 过程的概念,在解决与异种平台和应用环境相关的一些问题时,是非常有帮助的。 这样的问题包括:
互操作,它可以在过程的基础上得到解决而不是限于普通的情形。
分布,在基于已经存在的工具编写分布应用程序时,提供了充分的支持。
前向恢复,通过使用数据库持久记录过程中的每一步来得到保证。
监控,基于保存在数据库中的过程的当前状态和前状态来实现。
历史回溯,基于对存贮过程状态数据库的查询和数据挖掘工作来实现。
这些问题在许多不同的应用领域很普遍地出现,从虚拟企业和商业环境到软件工程和科学数据管理, 这说明了过程概念应用的广泛性。
对于地理信息系统而言,大部分的研究活动集中于以下一些问题:空间数据表现,索引,存储和检索。 可以说,这只是试图针对传统数据集进行数据库技术扩展的结果。 而空间过程问题,不仅仅只是与空间模型有关,下面用一个例子进行说明。
图16-21是一个典型的空间模型组合,形成应用于不同数据集的变换序列 。 例如,高程采样数据作为数值高程重建算法的输入,生成带有内插高程的地形图。 然后地形图被坡面分析程序使用,以提取不同坡面的坡长,坡度和坡向。 这些结果,连同该区域的土壤抽样数据和植被覆盖信息,被用于作为试图预测该区域未来侵蚀模式模型的输入数据。 植被覆盖数据通过综合分析土壤抽样数据,植被抽样数据和卫星图像得到。 植被覆盖数据也作为植被演替模型的输入数据,该模型根据预测的侵蚀数据,估算未来可能的植被覆盖变化。 在考虑到降水量的影响时,也是相似的逐步的过程。 图21表现了所有的空间模型组织在一起,形成一个复杂的操作集合,表现不同的地理现象。 图 16.20 图16-21:空间过程的例子:水土流失模型[G.Alonso] # 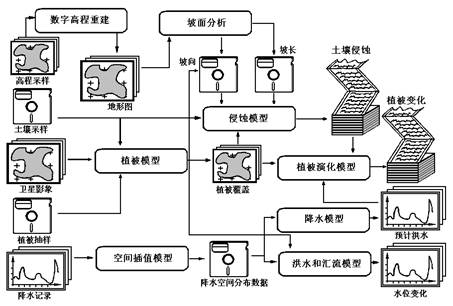
这个例子阐明了一些需求,很自然,这些需求与过程管理的需求非常相似。 下面列出这些必要的、简化的需求,包括模型语言,分布和并行以及查询能力。
模型语言:在任何一个过程支持系统中,其关键成分就是可以表述过程的语言。给定一个复杂的地理过程模型,模型语言必须是结构化的,允许嵌套,并且可以被方便地重用。任何地理过程应该可以方便地被用于构造一个更大的地理过程。此外,考虑到复杂的执行环境,该语言必须提供对事件和例外处理机制的支持。事件可以被用于在数据集发生改变时,通知系统并且触发执行模型,以产生更新的数据。类似地,考虑到例外,必须存在一个可靠的机制来处理它们,以避免系统偏离预先描述的行为,造成整个模型执行的退出。由于在工作流系统中,该语言必须允许定义和注册外部对象以及应用。在地理过程的应用中,更应该这样,这是因为在地理过程管理中,不论算法还是空间数据都将外在于系统,外部实体的注册是互操作性问题的基础。
分布和并行中的前向恢复:为了降低这种复杂的地理过程执行的开销,只要可能,它们的不同的步骤应该并行。一般来讲,我们假定基本的平台是一组(cluster)微机或工作站,不要求是相同的操作系统。地理过程中的每一个步骤都可以被指派到这一组中的不同的结点上,因此采用并行机制是模型固有的特征。同样地,多处理器的机器也采用类似的实现。作为其直接后果,并且由于模型的成本和执行它们所用的时间,必须有一种机制,以避免当发生错误时,所有的计算丢失。这就是前向恢复的概念,它可以从由于错误引起的中断处恢复执行。如果提供一个系统,其中复杂的地理过程只能从头到尾的执行而不能在中间中断,也不能动态修改地理过程以纠正错误,这样的系统将是无用的。通常的,构造一个地理过程与其说是为了得到其结果,不如说是测试相关地理模型的合法性和可用性。基于这些理由,系统必须支持单步执行,并且能够在任何执行点上停止,进行检查,作出改变以及恢复执行。这样的功能只能通过对地理过程执行的精确监测来实现。
依赖性查询能力:在地理过程中,如果对模型和输入数据不了解,那么就不能很好地解释利用该数据和模型产生的数据。这样就引出了那些众所周知的问题如“族系跟踪(Lineage tracking)”,“变化传播(Change propagation)”以及“版本”,这些概念与更加一般的过程中的历史跟踪没有什么不同。在这种环境中,将有这样一些典型的查询问题,例如“哪一个模型用到了算法X?”,“”如果数据集Y发生改变,将会产生什么结果?”以及“哪些数据用于产生数据Z?”。因此,系统必须支持如下的一些功能,包括:自动变化传播(当输入数据发生改变时,重新执行模型,以创建新版本的输出数据),变化通知以及过程控制(只要一个数据集存在,创建它所使用的模型将保留一个拷贝;同样的,只要有其它过程使用了一个子过程,也保留该子过程的拷贝),这样系统才能真正有用。只有具有合适的机制来跟踪数据之间的依赖性,并且有高效的方法从这些依赖性中提取信息,系统才能很好地提供上述功能。过程建模是当前软件工程一个重要的研究方向,通过形式化地描述开发过程,进而实现更加“精确”的过程管理,它同样可以应用于空间过程。由于过程本身的复杂度,使得难以建立完整的过程模型,利用配置管理工具,可以在一定程度上实现数据、模型乃至过程的控制管理。