seaborn.lmplot(*, x=None, y=None, data=None, hue=None, col=None, row=None, palette=None, col_wrap=None, height=5, aspect=1, markers='o', sharex=True, sharey=True, hue_order=None, col_order=None, row_order=None, legend=True, legend_out=True, x_estimator=None, x_bins=None, x_ci='ci', scatter=True, fit_reg=True, ci=95, n_boot=1000, units=None, seed=None, order=1, logistic=False, lowess=False, robust=False, logx=False, x_partial=None, y_partial=None, truncate=True, x_jitter=None, y_jitter=None, scatter_kws=None, line_kws=None, size=None)¶绘图数据和回归模型适合整个网格。
此功能结合 regplot() 和 FacetGrid . 它的目的是作为一个方便的接口来拟合一个数据集的条件子集的回归模型。
当考虑如何将变量分配给不同的方面时,一般的规则是使用 hue 最重要的比较,其次是 col 和 row . 但是,请始终考虑您的特定数据集以及您正在创建的可视化的目标。
估计回归模型有许多相互排斥的选项。看到了吗 tutorial 更多信息。
此函数的参数跨越中的大多数选项 FacetGrid ,尽管有时您可能希望使用该类和 regplot() 直接。
输入变量;这些变量应该是 data .
整洁(“长格式”)数据帧,其中每列是一个变量,每行是一个观察值。
定义数据子集的变量,这些数据将绘制在网格中的不同面上。看到了吗 *_order 用于控制此变量的级别顺序的参数。
用于不同级别的 hue 变量。应该是可以解释的东西 color_palette() ,或将色调级别映射到matplotlib颜色的字典。
以此宽度“包装”列变量,以便列面跨多行。与…不相容 row 方面。
每个面的高度(英寸)。另请参见: aspect .
每个面的纵横比,以便 aspect * height 以英寸为单位给出每个面的宽度。
Markers for the scatterplot. If a list, each marker in the list will be
used for each level of the hue variable.
如果为真,则行和面将在x轴和y轴之间共享。
分面变量的顺序。默认情况下,这将是级别的显示顺序 data 或者,如果变量是分类变量,则为分类顺序。
如果 True 还有一个 hue 变量,添加图例。
如果 True ,图形大小将扩展,图例将绘制在右中的绘图外部。
将此函数应用于 x 并绘制出估算结果。这在以下情况下很有用 x 是离散变量。如果 x_ci 给出了该估计的自举和置信区间。
垃圾箱 x 将变量转化为离散的数据箱,然后估计中心趋势和置信区间。这种分块只影响散点图的绘制方式;回归仍然适用于原始数据。此参数可解释为大小均匀(无需间隔)的料仓数量或料仓中心的位置。使用此参数时,表示 x_estimator 是 numpy.mean .
绘制离散值的中心趋势时使用的置信区间的大小 x .如果 "ci" ,遵从 ci 参数。如果 "sd" ,跳过自举,并显示每个箱中观测值的标准偏差。
如果 True ,绘制一个包含基本观测值的散点图(或 x_estimator 价值观)。
如果 True ,估计并绘制与 x 和 y 变量。
回归估计的置信区间大小。这将使用围绕回归线的半透明条带绘制。置信区间是使用bootstrap估计的;对于大型数据集,建议通过将此参数设置为None来避免这种计算。
用于估计 ci . 默认值试图平衡时间和稳定性;您可能希望为绘图的“最终”版本增加此值。
data 可选中的变量名如果 x 和 y 观测值嵌套在采样单位中,可在此处指定。在计算置信区间时,通过对单位和观测值(单位内)进行重采样的多级引导,将考虑到这一点。否则,这不会影响如何估计或绘制回归。
种子或随机数发生器可复制的引导。
如果 order 大于1,使用 numpy.polyfit 估计多项式回归。
如果 True ,假设 y 是一个二进制变量,使用 statsmodels 估计logistic回归模型。请注意,这比线性回归的计算量大得多,因此您可能希望减少引导重采样的数量 (n_boot )或设置 ci 一点也没有。
如果 True 使用 statsmodels 估计非参数lowess模型(局部加权线性回归)。请注意,目前无法为此类模型绘制置信区间。
如果 True 使用 statsmodels 稳健回归。这将降低异常值的权重。请注意,这比标准线性回归的计算量要大得多,因此您可能希望减少引导重采样的数量 (n_boot )或设置 ci 一点也没有。
如果 True ,估计y~log(x)形式的线性回归,但在输入空间绘制散点图和回归模型。请注意 x 必须是积极的,这样才能起作用。
data 或矩阵字符串输入混杂变量回归出 x 或 y 打印前的变量。
如果 True ,回归线受数据限制。如果 False ,它延伸到 x 轴限制。
将此大小的均匀随机噪声添加到 x 或 y 变量。拟合回归后,噪声被添加到数据的副本中,并且只影响散点图的外观。这在绘制采用离散值的变量时非常有用。
要传递到的其他关键字参数 plt.scatter 和 plt.plot .
参见
笔记
这个 regplot() 和 lmplot() 功能是密切相关的,但前者是一个轴级功能,后者是一个图形级功能,结合 regplot() 和 FacetGrid .
实例
这些示例集中在基本回归模型图上,以展示各种镶嵌面选项;请参见 regplot() 用于演示绘制数据和模型的其他选项的文档。还有其他示例说明如何使用 FacetGrid 博士学位。
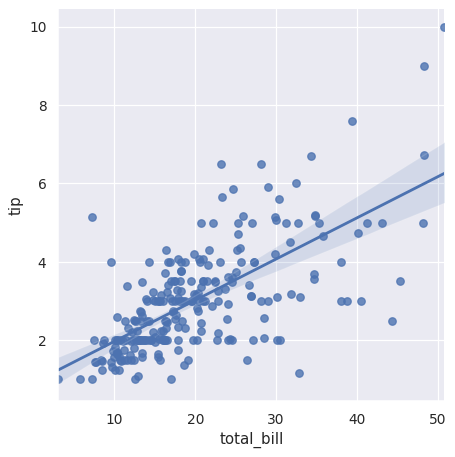
绘制两个变量之间的简单线性关系:
>>> import seaborn as sns; sns.set_theme(color_codes=True)
>>> tips = sns.load_dataset("tips")
>>> g = sns.lmplot(x="total_bill", y="tip", data=tips)
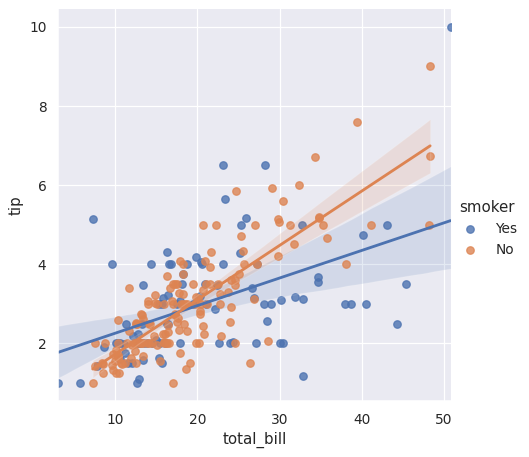
在第三个变量上设置条件并以不同颜色绘制级别:
>>> g = sns.lmplot(x="total_bill", y="tip", hue="smoker", data=tips)
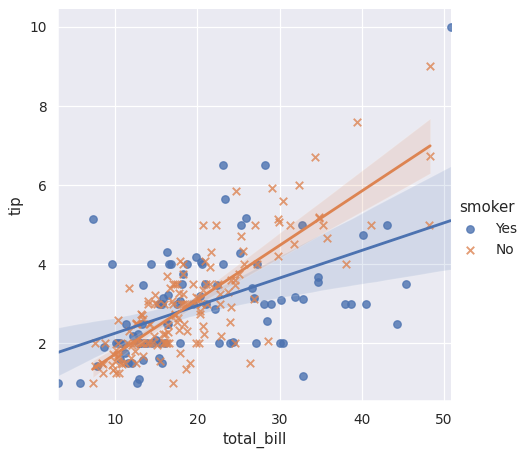
使用不同的标记和颜色,这样绘图将更容易复制为黑白:
>>> g = sns.lmplot(x="total_bill", y="tip", hue="smoker", data=tips,
... markers=["o", "x"])
使用不同的调色板:
>>> g = sns.lmplot(x="total_bill", y="tip", hue="smoker", data=tips,
... palette="Set1")
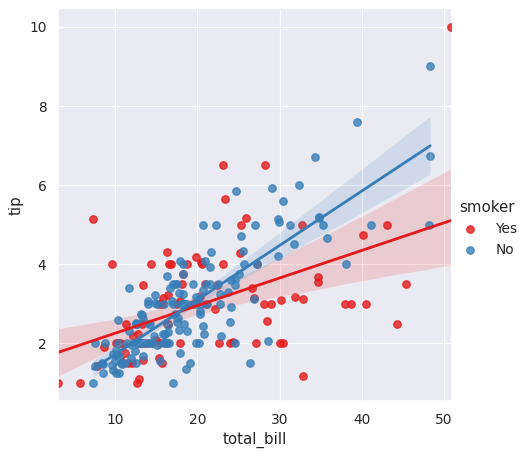
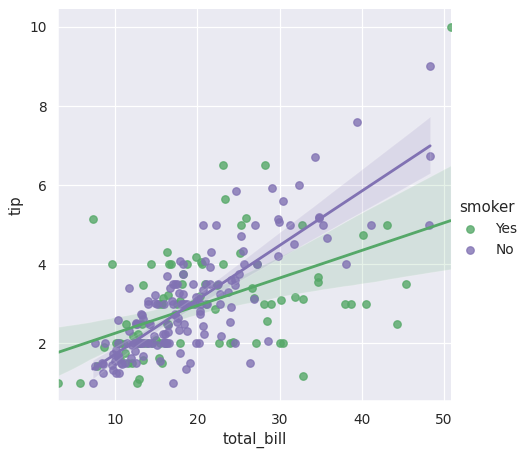
地图 hue 使用字典将级别转换为颜色:
>>> g = sns.lmplot(x="total_bill", y="tip", hue="smoker", data=tips,
... palette=dict(Yes="g", No="m"))
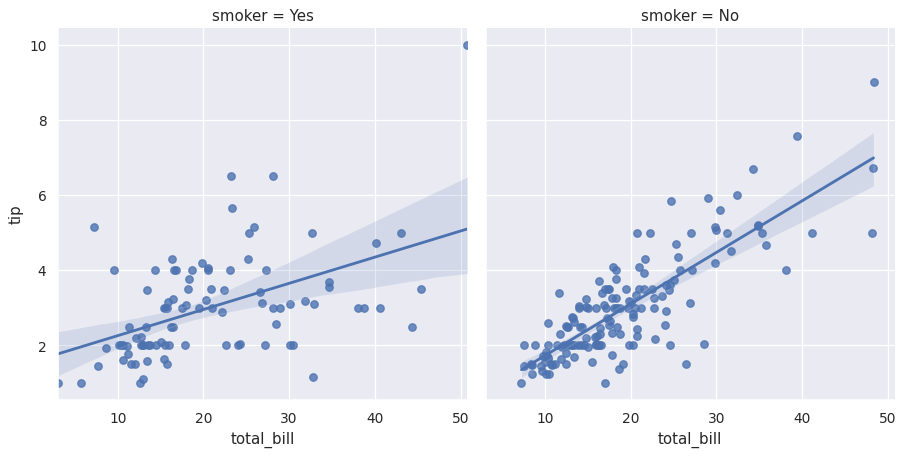
在不同的列中绘制第三个变量的级别:
>>> g = sns.lmplot(x="total_bill", y="tip", col="smoker", data=tips)
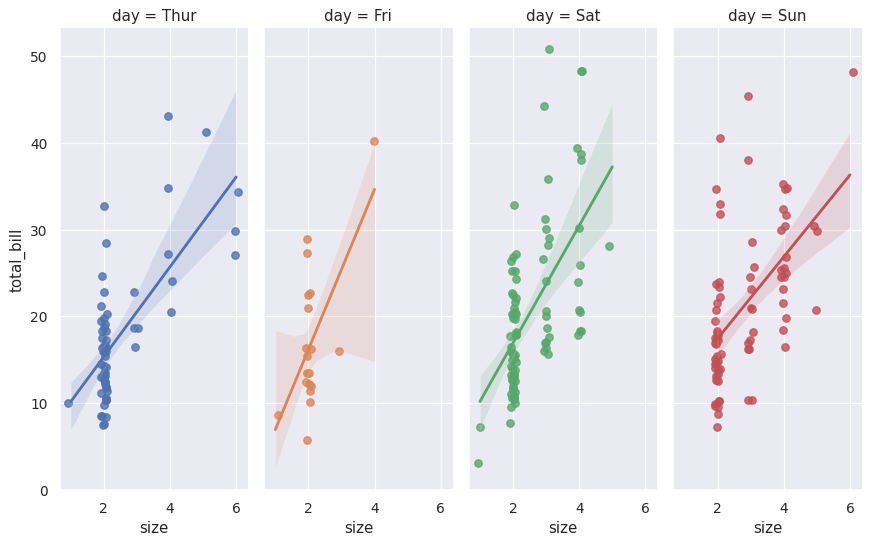
更改镶嵌面的高度和纵横比:
>>> g = sns.lmplot(x="size", y="total_bill", hue="day", col="day",
... data=tips, height=6, aspect=.4, x_jitter=.1)
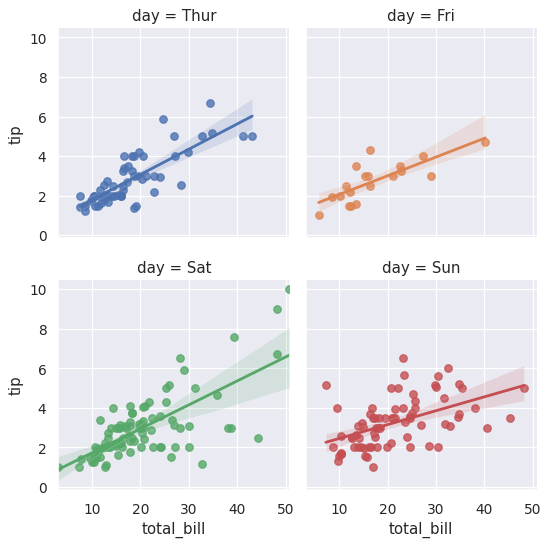
将列变量的级别包装为多行:
>>> g = sns.lmplot(x="total_bill", y="tip", col="day", hue="day",
... data=tips, col_wrap=2, height=3)
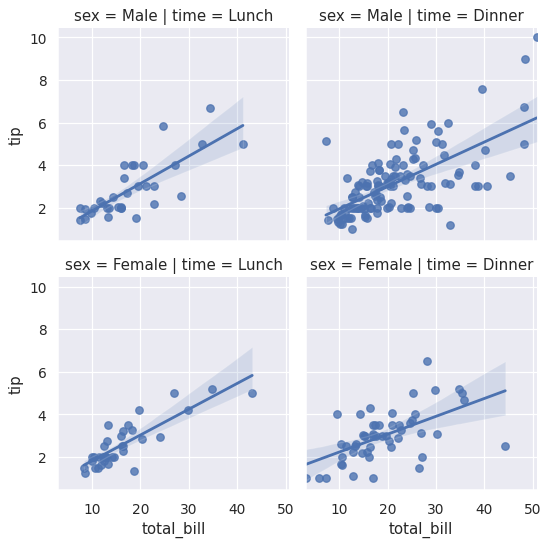
设置两个变量以形成完整网格:
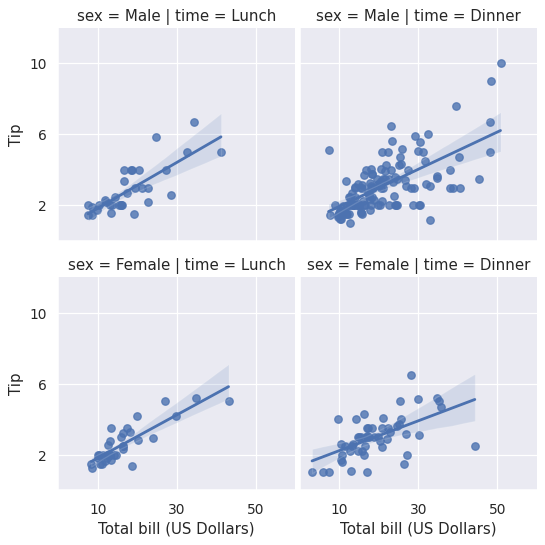
>>> g = sns.lmplot(x="total_bill", y="tip", row="sex", col="time",
... data=tips, height=3)
对返回的 FacetGrid 实例进一步调整绘图:
>>> g = sns.lmplot(x="total_bill", y="tip", row="sex", col="time",
... data=tips, height=3)
>>> g = (g.set_axis_labels("Total bill (US Dollars)", "Tip")
... .set(xlim=(0, 60), ylim=(0, 12),
... xticks=[10, 30, 50], yticks=[2, 6, 10])
... .fig.subplots_adjust(wspace=.02))