Python+TensorFlow 从零搭建并部署智能聊天机器人
访问量: 10 次浏览
在Python中使用TensorFlow部署一个聊天机器人
在这篇文章中,你将学习如何使用Tensorflow部署一个聊天机器人。聊天机器人基本上是一个机器人(一个程序),它可以像人类一样谈论和回答各种问题。我们将使用一些Python模块来做到这一点。
本文分为两部分:
首先,我们将训练聊天机器人模型,然后在第二部分,我们将学习如何让它工作并对用户的各种输入做出反应。
需要的模块:
- random – 该模块用于生成聊天机器人的随机响应。
- json – 从json文件中读取
- pickle – 将数据保存到文件中
- tensorflow – 用于训练神经网络。它是一个开源的机器学习库。
- numpy
– 它是一个用于处理数组的Python库。 - nltk – 它是建立Python程序以处理人类语言数据的一个领先平台。
训练聊天机器人模型
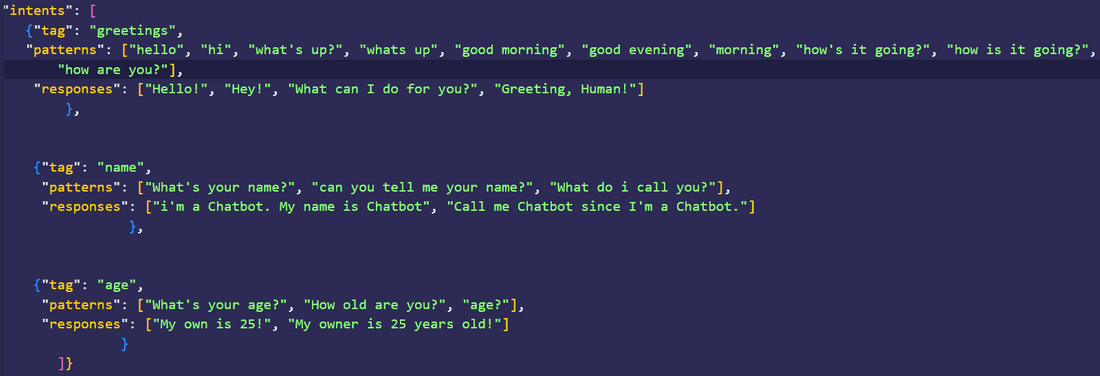
我们要做的第一件事是训练聊天机器人模型。为了做到这一点,我们要创建一个名为 “intense.json “的文件,在其中写下所有的意图、标签和我们的聊天机器人要回应的词语或短语。
第1步:创建一个 “intense.json”:
这里我们只添加了三个标签,只是为了展示它是如何工作的。你可以添加很多的标签!
第2步:创建一个 “training.py”:
下一步是训练我们的模型。我们将使用一个叫做WordNetLemmatizer()的类,它将给出聊天机器人可以识别的词的词根。例如,对于hunting、hunter、hunts和hunted,WordNetLemmatizer()类的lemmatize功能将给出 “hunt”,因为它是词根。
- 创建一个WordNetLemmatizer()类对象。
- 从 “intense.json “文件中读取内容并将其存储到变量 “intents “中。接下来,初始化空列表来存储内容。
- 接下来,我们有一个叫做word_tokenize(para)的函数。它接收一个句子作为参数,然后返回一个包含该句子所有单词的字符串的列表。在这里,我们对模式进行标记,然后将它们追加到一个列表’words’中。因此,最后,这个列表’words’将拥有’pattern’列表中的所有单词。
- 在文档中,我们以元组的形式拥有所有的模式和它们的标签。
- 现在,使用列表理解,我们将修改上面创建的列表 “单词”,并存储单词的 “词根”,或简单地说,词根。
- 使用pickle模块的dump()函数,将 “词 “和 “类 “的数据转储到同名的二进制文件中。
# importing the required modules.
import random
import json
import pickle
import numpy as np
import nltk
from keras.models import Sequential
from nltk.stem import WordNetLemmatizer
from keras.layers import Dense, Activation, Dropout
from keras.optimizers import SGD
lemmatizer = WordNetLemmatizer()
# reading the json.intense file
intents = json.loads(open("intense.json").read())
# creating empty lists to store data
words = []
classes = []
documents = []
ignore_letters = ["?", "!", ".", ","]
for intent in intents['intents']:
for pattern in intent['patterns']:
# separating words from patterns
word_list = nltk.word_tokenize(pattern)
words.extend(word_list) # and adding them to words list
# associating patterns with respective tags
documents.append(((word_list), intent['tag']))
# appending the tags to the class list
if intent['tag'] not in classes:
classes.append(intent['tag'])
# storing the root words or lemma
words = [lemmatizer.lemmatize(word)
for word in words if word not in ignore_letters]
words = sorted(set(words))
# saving the words and classes list to binary files
pickle.dump(words, open('words.pkl', 'wb'))
pickle.dump(classes, open('classes.pkl', 'wb'))
第3步:现在我们需要将我们的数据分类为0和1,因为神经网络的工作对象是数值,而不是字符串或其他东西。
- 创建一个名为training的空列表,我们将在其中存储用于训练的数据。同时创建一个output_empty列表,它将存储与intense.json中的类一样多的0。
- 接下来,我们将创建一个袋子,用来存储0和1。(0,如果该词不在模式中,1,如果该词在模式中)。为了做到这一点,我们将遍历文档列表,如果它不在模式中,就将1追加到’袋’中,否则就是0。
- 现在将这个训练集进行洗牌,使其成为一个numpy数组。
- 将由1和0组成的训练集分成两部分,即train_x和train_y。
# we need numerical values of the
# words because a neural network
# needs numerical values to work with
training = []
output_empty = [0]*len(classes)
for document in documents:
bag = []
word_patterns = document[0]
word_patterns = [lemmatizer.lemmatize(
word.lower()) for word in word_patterns]
for word in words:
bag.append(1) if word in word_patterns else bag.append(0)
# making a copy of the output_empty
output_row = list(output_empty)
output_row[classes.index(document[1])] = 1
training.append([bag, output_row])
random.shuffle(training)
training = np.array(training)
# splitting the data
train_x = list(training[:, 0])
train_y = list(training[:, 1])
第四步:我们已经来到了聊天机器人模型的模型构建部分。在这里,我们将部署一个顺序模型,我们将在上面准备的数据集上训练它。
- Add()。该函数用于在神经网络中添加层。
- Dropout()。该函数用于避免过度拟合
# creating a Sequential machine learning model
model = Sequential()
model.add(Dense(128, input_shape=(len(train_x[0]), ),
activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(64, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(len(train_y[0]),
activation='softmax'))
# compiling the model
sgd = SGD(lr=0.01, decay=1e-6, momentum=0.9, nesterov=True)
model.compile(loss='categorical_crossentropy',
optimizer=sgd, metrics=['accuracy'])
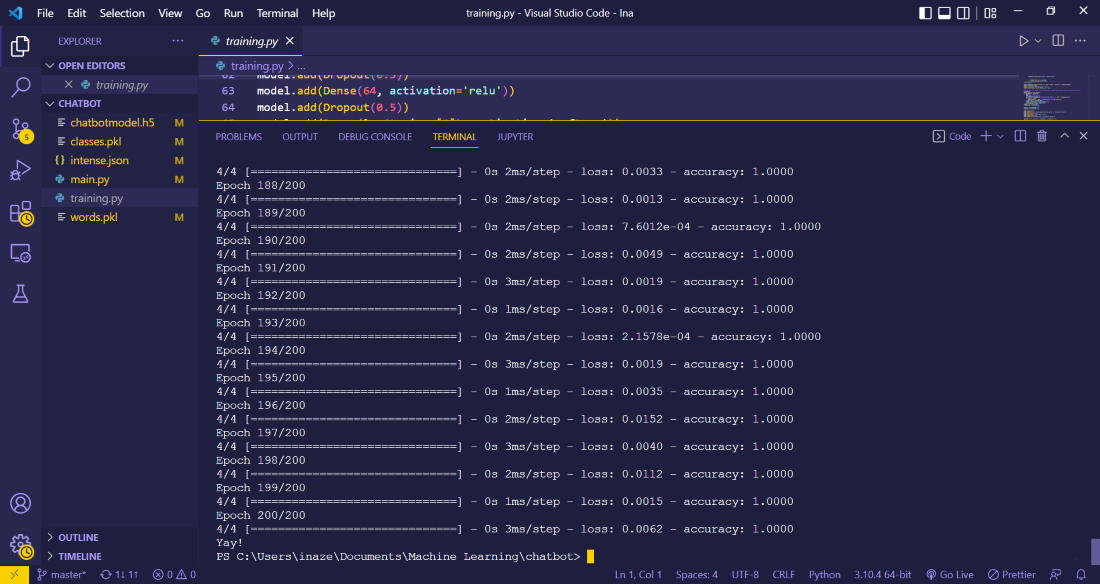
hist = model.fit(np.array(train_x), np.array(train_y),
epochs=200, batch_size=5, verbose=1)
# saving the model
model.save("chatbotmodel.h5", hist)
# print statement to show the
# successful training of the Chatbot model
print("Yay!")
输出:
创建一个main.py来运行聊天工具
我们已经完成了模型的训练,现在我们需要创建主文件,使聊天机器人模型工作并对我们的输入做出反应。
第1步:
要开始,请导入以下模块。
# required modules
import random
import json
import pickle
import numpy as np
import nltk
from keras.models import load_model
from nltk.stem import WordNetLemmatizer
第2步:初始化下列类和文件内容
。
lemmatizer = WordNetLemmatizer()
# loading the files we made previously
intents = json.loads(open("intense.json").read())
words = pickle.load(open('words.pkl', 'rb'))
classes = pickle.load(open('classes.pkl', 'rb'))
model = load_model('chatbotmodel.h5')
第3步:我们将在这里定义3个函数
。
clean_up_sentences(sentence)
– 这个函数将从我们要输入的句子中分离出单词。
def clean_up_sentences(sentence):
sentence_words = nltk.word_tokenize(sentence)
sentence_words = [lemmatizer.lemmatize(word)
for word in sentence_words]
return sentence_words
bagw(sentence):
这个函数将把1追加到一个列表变量’bag’中,如果这个词包含在我们的输入中,并且也出现在先前创建的单词列表中。
- 首先,我们将使用上面定义的函数从输入中分离出 “根 “字,然后在下一行,初始化一个名为bag的列表变量,该变量将包含与单词列表长度相同数量的0。
- 使用嵌套的for循环,我们将检查输入的单词是否也在单词列表中。如果是,我们就把1加到袋子里,否则就保持0。
- 返回一个列表变量bag的numpy数组,现在包含1和0。
def bagw(sentence):
# separate out words from the input sentence
sentence_words = clean_up_sentences(sentence)
bag = [0]*len(words)
for w in sentence_words:
for i, word in enumerate(words):
# check whether the word
# is present in the input as well
if word == w:
# as the list of words
# created earlier.
bag[i] = 1
# return a numpy array
return np.array(bag)
predict_class(sentence):
该函数将预测用户输入的句子的类别。
- 使用上面定义的函数初始化一个变量bow,它将包含一个0和1的NumPy数组。使用predict()函数,我们将根据用户的输入来预测结果。
- 初始化一个变量ERROR_THRESHOLD,如果数值大于ERROR_THRESHOLD,则从’res’中追加,然后用排序函数进行排序。
- 使用列表变量return_list,存储intense.json文件中的标签或类。
def predict_class(sentence):
bow = bagw(sentence)
res = model.predict(np.array([bow]))[0]
ERROR_THRESHOLD = 0.25
results = [[i, r] for i, r in enumerate(res)
if r > ERROR_THRESHOLD]
results.sort(key=lambda x: x[1], reverse=True)
return_list = []
for r in results:
return_list.append({'intent': classes[r[0]],
'probability': str(r[1])})
return return_list
get_response(intents_list, intents_json):
该函数将从用户输入的句子/单词所属的类别中随机打印一个响应。
- 首先,我们初始化一些必要的变量,如标签、list_of_intents和结果。
- 如果标签与list_of_intents中的标签相匹配,则使用随机模块的choice()方法,在一个名为result的变量中存储一个随机响应。
- 返回结果。
def get_response(intents_list, intents_json):
tag = intents_list[0]['intent']
list_of_intents = intents_json['intents']
result = ""
for i in list_of_intents:
if i['tag'] == tag:
# prints a random response
result = random.choice(i['responses'])
break
return result
print("Chatbot is up!")
第4步:最后,我们将初始化一个无限的while循环,提示用户输入并打印出聊天机器人的回应。
while True:
message = input("")
ints = predict_class(message)
res = get_response(ints, intents)
print(res)
main.py的内容如下:
import random
import json
import pickle
import numpy as np
import nltk
from keras.models import load_model
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
intents = json.loads(open("intense.json").read())
words = pickle.load(open('words.pkl', 'rb'))
classes = pickle.load(open('classes.pkl', 'rb'))
model = load_model('chatbotmodel.h5')
def clean_up_sentences(sentence):
sentence_words = nltk.word_tokenize(sentence)
sentence_words = [lemmatizer.lemmatize(word)
for word in sentence_words]
return sentence_words
def bagw(sentence):
sentence_words = clean_up_sentences(sentence)
bag = [0]*len(words)
for w in sentence_words:
for i, word in enumerate(words):
if word == w:
bag[i] = 1
return np.array(bag)
def predict_class(sentence):
bow = bagw(sentence)
res = model.predict(np.array([bow]))[0]
ERROR_THRESHOLD = 0.25
results = [[i, r] for i, r in enumerate(res)
if r > ERROR_THRESHOLD]
results.sort(key=lambda x: x[1], reverse=True)
return_list = []
for r in results:
return_list.append({'intent': classes[r[0]],
'probability': str(r[1])})
return return_list
def get_response(intents_list, intents_json):
tag = intents_list[0]['intent']
list_of_intents = intents_json['intents']
result = ""
for i in list_of_intents:
if i['tag'] == tag:
result = random.choice(i['responses'])
break
return result
print("Chatbot is up!")
while True:
message = input("")
ints = predict_class(message)
res = get_response(ints, intents)
print(res)