Choropleth Maps - 数据分类指南
访问量: 654 次浏览
什么是 Choropleth Maps?
Choropleth maps 根据定量数据使用不同的阴影和颜色。
有很多种方法可以对数据进行分类,
例如,等间隔、分位数、自然间断点和间断点。
然而它们之间有什么区别呢?
今天,您将在本文的数据分类指南中学习,
如何选择最好的方法对 Choropleth maps 中的数据进行分类。
选择课程数量
首先需要聚合基于多个类的数据。
当有更多的类时,
会得到更多的变化,
有时会使分离阴影变得更加困难。
如果想测试不同的阴影,ColorBrewer
有一个颜色建议工具。
例如,以下有10 个类:
提供较少的类之间的分离,
例如下面的 5 个类。

毕竟,决定的类的数量实际上取决于地图的用途。
选择数据分类方法
其次需要决定如何对数据进行分类。
换言之,数据分类用边界将数据排列成不同的类,
可以使用等间隔模式分隔类:
或者,可以选择一种分位数类型的分类器,
它以不同的方式排列数据(下面将详细介绍)。
每种数据分类技术都会生成独特的 Choropleth maps。
但他们都给地图读者描绘了一个不同的故事。
我们必须意识到的是,
在每个地方地图中使用的是相同的数据,
但真正改变的是如何对数据进行分类。
创建 Choropleth maps
最重要且必须意识到的是,
对于我们创建的每一个 Choropleth maps,
都使用相同的数据。
发生变化的是对数据进行分类的方式。
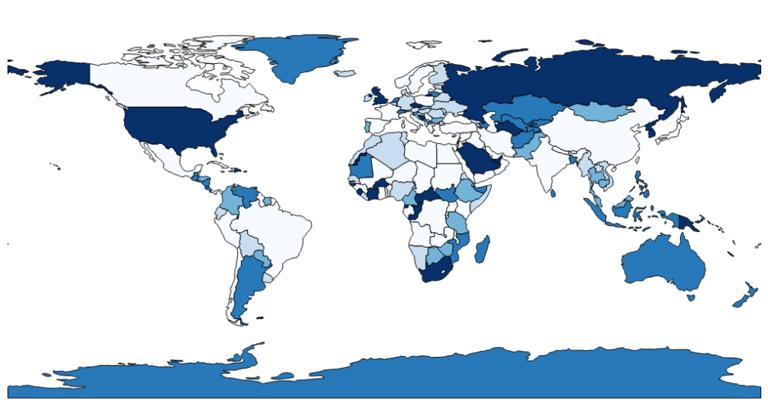
在此示例中,计算国家、地区名称中的字母数。
例如:
马里、古巴、秘鲁等是四个字母的国家。
而波斯尼亚和黑塞哥维那有 22 个字符。
如果绘制出4到22个字符,它会有很多颜色。
例如,四个字母的国家、地区是最浅的绿色阴影。
随着字母数的增加,阴影变暗。
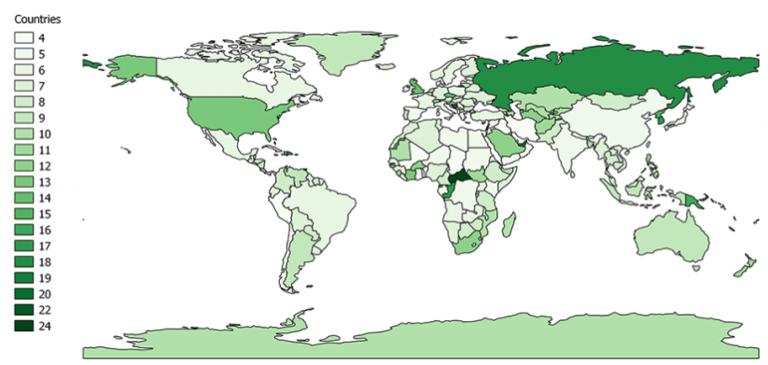
标题按国家、地区字符数绘制的 Choropleth maps 阴影。
这就是使用数据分类的原因。
当按类别分组时,
阴影较少,因此按组聚合数据。
那么如何对数据进行分组呢?
首先,让我们尝试将类分成均匀间隔的组,
如下面的等间隔,
看看会发生什么。
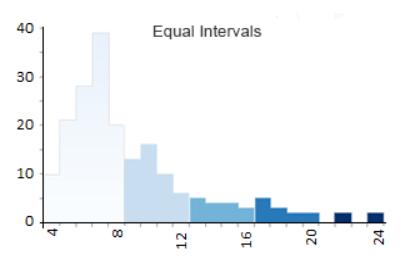
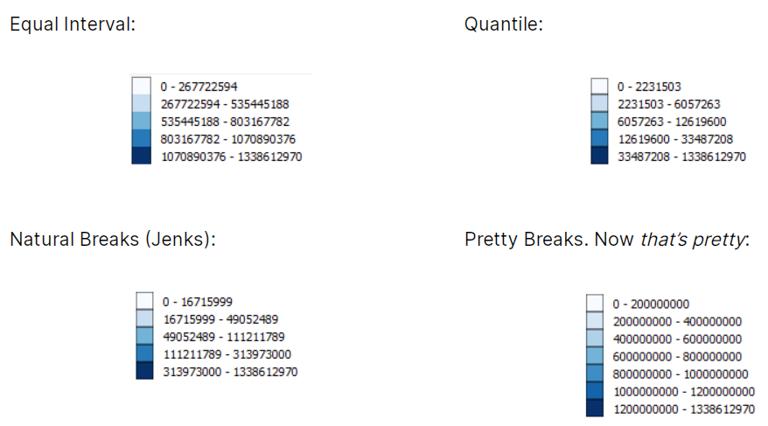
等区间数据分类
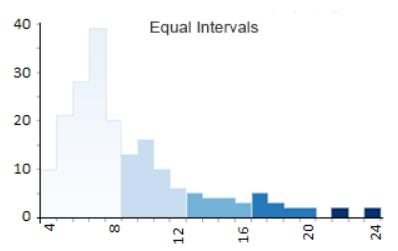
- Class 1: 4 – 8(113 个国家有四个、五个、六个、七个或八个字母)
- Class 2: 8 – 12 (41)
- Class 3: 12 – 16 (12)
- Class 4: 16 – 20 (8)
- Class 5: 20 – 24 (2)
一个国家的最小字符数是 4,
例如秘鲁。
最大字符数为 24 ,
即中非共和国。
当在地图上绘制每个国家及其字符数时,
它看起来如下图(括号表示计数):
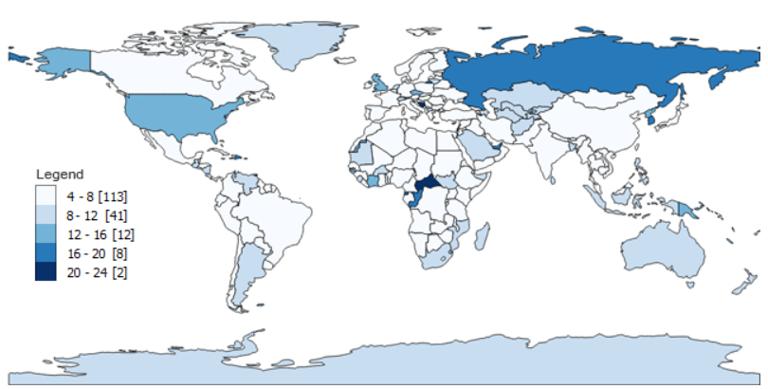
等区间数据分类用最小值减去最大值(24-4=20)。
在本文示例中,生成了 5 个类,
但类的数量完全由您决定。
将 20 除以 5,
得到一个区间 ( 20/5=4 )。
等间隔 Choropleth maps 会导致每个类别的国家数量不相等。
例如,第 1 类有176 个国家中的113 个国家,
有四个、五个、六个和七个字母,
然而只有 2 个国家的字母超过 20 个。
因此,与只有 2 个深色阴影相比,
这张地图显示了更多的浅色阴影。
如果希望每个类别中的国家/地区数量接近相等,
会发生什么情况呢?
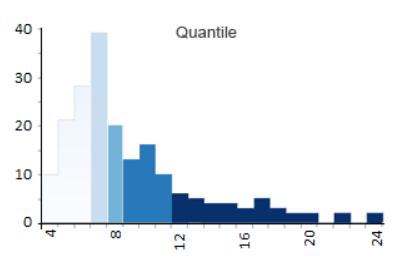
分位数(等计数)分类
分位数图尝试对 5 个类中的每个类中相同数量的要素进行分箱。
换言之,分位数图试图排列组,
使它们具有相同的数量。
因此,阴影在分位数类型的地图中看起来分布均匀。
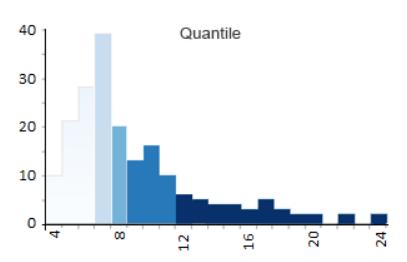
- Class 1: 4 – 6(56 个国家有 4、5 或 6 个字母的名称)
- Class 2: 6 – 7 (38)
- Class 3: 7 – 8 (19)
- Class 4: 9 – 11 (36)
- Class 5: 12 – 24 (27)
分位数图采用特征数量(本文示例中是 176 个国家)。
它将总数除以类数以获得平均值 ( 176/5=35.2 )。
最后,分位数图计算每组中的数量,
并尽可能接近平均值排列。
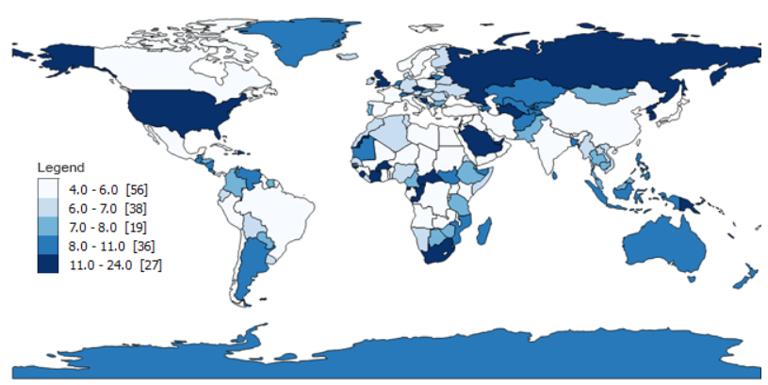
可以看到每个类的计数看起来非常相似并且接近 35.2。
对于每一类,计数都不会太多或太少。
尽管分位数 Choropleth maps 采用平衡风格,
但它们也可能具有误导性。
因为人们倾向于查看其中一种色调并将其归入同一类别。
Natural Breaks (Jenks) 分类
关于 Natural Breaks (Jenks) 分类,
首先要记住它是 Choropleth maps 的优化方法。
简而言之,它会安排每个分组,
因此每个类别或阴影的变化较小。
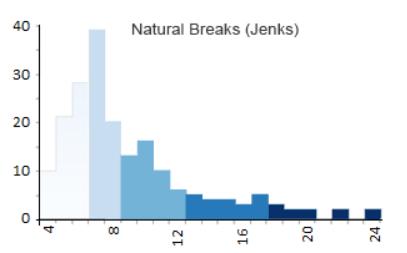
- Class 1: 4 – 6 (56)
- Class 2: 6 – 8 (57)
- Class 3: 8 – 12 (41)
- Class 4: 12 – 18 (18)
- Class 5: 18 – 24 (4)
Natural Breaks (Jenks) 采用迭代方法,
将类之间的偏差平方和与数组均值进行比较。
该算法使用方差拟合优度,
其中 1 为完美拟合,0 为差拟合。
Natural Breaks 数据分类方法的创始人是一位名叫 George Frederick Jenks 的制图师。
他专门研究人们在看地图时的眼球运动。
这张地图的结果看起来也很棒。
我们可以看到这种数据分类方法如何最大限度地减少每个组中的差异。
由于有很多较短的国家、地区名称,
它会找到合适的类别范围。
但它仍然设法将具有较长国家、地区名称的异常值归为一类。
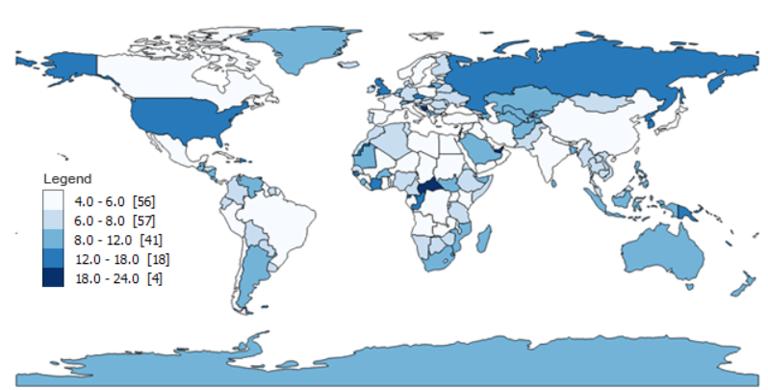
标准偏差分类
标准偏差是一种统计技术类型的地图,
基于数据与平均值的差异程度。
测量数据的均值和标准差,
每个标准偏差都会成为 Choropleth maps 中的一个类。
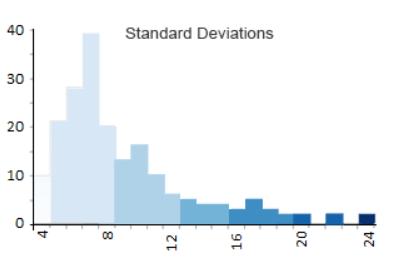
在本文的示例中,
平均字符数约为 8.5,标准差为 3.7 个字符。
因此,所有具有 5 到 8 个字符的国家、地区将被置于 0 到 -1 标准差分组中。
同样,具有 9 到 12 个字母的国家、地区在 0 到 1 个标准偏差范围内分组,
如下所示:
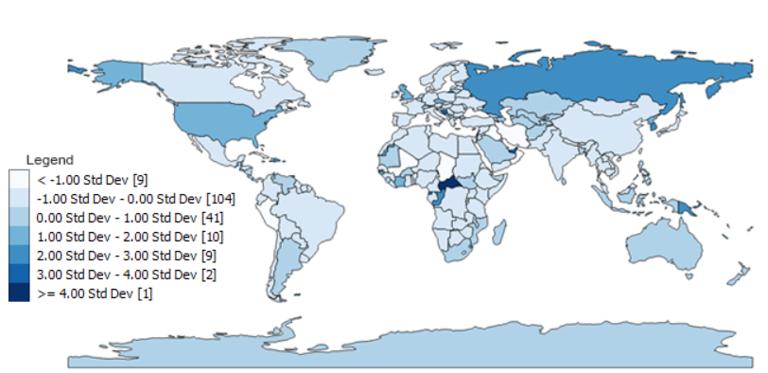
- Class 1: <-1 σ (9)
- Class 2: -1 to 0 σ (104)
- Class 3: 0 to 1 σ (41)
- Class 4: 1 to 2 σ (10)
- Class 5: 2 to 3 σ (9)
- Class 6: 3 to 4 σ (2)
- Class 7: >=4 σ (1)
作为输出的原始类别需要向读者说明一下。
平均数是多少?每个标准偏差的范围是多少?
尽管存在这些不一致,
标准偏差类型的地图可能是最合适的地图之一,
所有 4 个字母的国家/地区均 <-1 标准差,
有 5 到 8 个字母的国家是 -1 到 0 的标准差,
一个 24 个字母的国家、地区超过 4 个标准差,
因为它与平均值 8.5 的极端偏差。
Pretty Breaks 分类
如果想要整数在范围内,
那么应该选择 Pretty Breaks。
所有 “Pretty Breaks” 分类都是将每个突破点向上或向下舍入。
因此,它将不再有599.364的断点,
而是变成600000个断点。
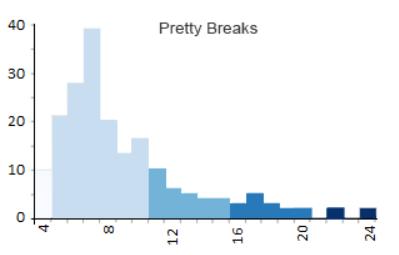
在此示例中,
很难看出数字有多圆(按5分组),
因为上面所有的例子都会产生圆数字。
然而当有大量的人口估计(见下文)时,
它会产生 Pretty Breaks。
- Class 1: 4 – 5 (29)
- Class 2: 5 – 10 (111)
- Class 3: 10 – 15 (24)
- Class 4: 15 – 20 (10)
- Class 5: 20 – 24 (2)
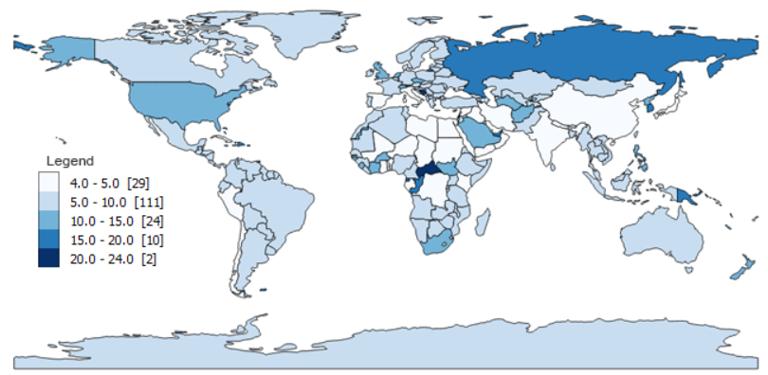
由于四舍五入,
Pretty Breaks 也会对决定的课程数量非常挑剔。
以下是当查看所有数据分类技术时,‘
人口估计值的比较:
Choropleth maps 使用不同的着色来显示定义区域中的数量或值。
通常情况下,
地图制作者使用一种数据分类来制作自己独特的 Choropleth maps。
每种数据分类方法对读者的影响不同。
在 GIS 中对数据进行分类有几种方法。
我们已经用 Choropleth maps 的不同示例概述了它们的差异。
利用本指南对犯罪率、教育水平和政治等几乎所有内容进行分类。
本文链接 :Choropleth Maps - 数据分类指南