地理和 GIS 中的空间模式
访问量: 378 次浏览

空间模式显示了地球上事物的相互联系方式。 这些图案可以是天然的或人造的。 当使用 GIS 时, 可以看到事物的位置以及它们之间的关系。 如今,让我们关注地理和 GIS 领域的空间模式。
点分布的类型
点分布是将特定位置制图为地图上的单个点的方式。 这些点可以代表任何东西。 例如,它们可以显示森林中树木的位置, 或者它们可能是城市中房屋的地址。
通过分析点分布, 我们可以识别空间模式。 例如,可以对点进行聚类或生成热图。 稍后会详细介绍这一点。 首先,我们来讨论一下点分布的类型。
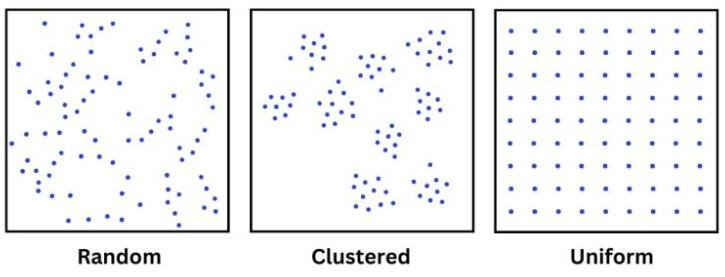
随机分布
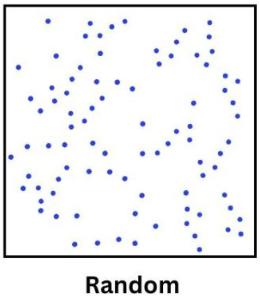
当点分散在一个区域且没有任何可预测的模式时, 就会出现随机点分布。 这意味着这些点没有显示出任何清晰的聚类或它们之间的规则间距。
例如, 地球上的陨石着陆点可能呈现随机分布。 当它们攻击时, 位置是相互独立的。 不过对不明飞行物目击事件感到好奇。
聚类点分布
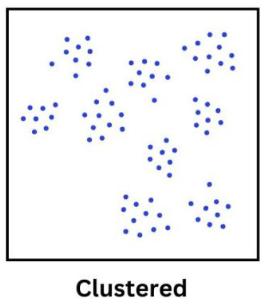
聚类点分布是指点聚集在某些区域中。 这种模式表明这些点具有相似的因素, 导致它们聚集。 这些高浓度区域还可以指示高度活动或兴趣的区域。
例如, 围绕一个受欢迎的湖泊建造的房屋可能会形成集群分布, 这表明人们更喜欢住在靠近水的地方, 另一个例子是沿构造板块边界的地震位置。
均匀分布
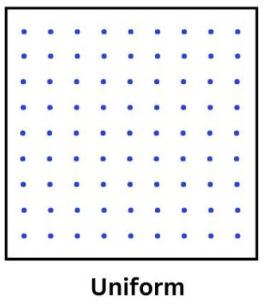
当点在区域内均匀分布时, 就会出现均匀点分布。 它们通常表现出一致的分布模式。 它通常表示一种故意的排列, 导致规则的间距。
例如,林地中等距离种植的树木就是均匀点分布的显示。 类似地, 另一个例子是高速公路上等间隔的路灯, 两者都展示了地理上刻意的均匀间距。
寻找空间模式
我们使用地理处理和数据可视化来识别空间模式, 每一项都可以帮助发现跨地理区域的数据分布和关系。
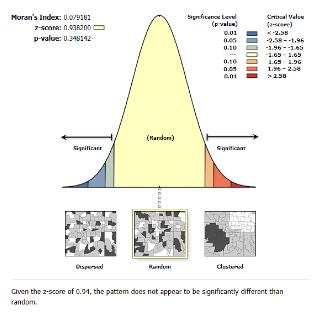
Moran's I
Moran's I 提供从 -1 到 1 的聚类数值度量。 具体来说, 它是我们用来测量空间自相关的统计量。
我们使用 Moran's I 来辨别相似或不相似的值是否在地图中聚集在一起, 它有助于理解特征是随机分布还是聚集在一起。
热图

热图使用颜色来显示密度或大小, 这使得很容易发现高度集中的区域。 例如,它们非常适合显示犯罪率或人口密度。
正因为如此, 我们可以快速识别问题区域或需要服务的区域。 因此,热图是可视化空间模式的独特工具。
地图
地图扭曲地理区域的形状和大小来表示特定的数据变量。 例如,高人口值将扩大多边形的大小。
地图有不同的风格。例如, 有密度均衡、Dorling 和非连续制图。 无论哪种类型, 区域的大小都会发生变化以反映其所代表的数据的值。
点聚类
点聚类根据地图上的位置对彼此靠近的数据点进行分组。 它表示任何特征高度集中的区域。 因此,通过发现这些簇, 我们可以了解特征集中在哪里。 虽然这有助于识别空间数据的模式, 但它也可以指导更好的决策。
地理回归
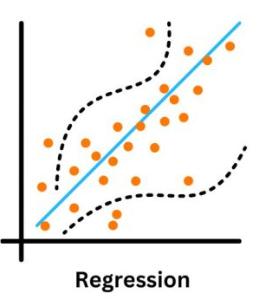
地理加权回归 (GWR)考虑数据点的地理位置来建模变量关系。 例如,GWR 可能会模拟鹿如何喜欢特定的栖息地。
传统的回归模型假设因变量和自变量之间的关系在任何地方都是相同的。 但在现实场景中并不总是如此, 空间模式的出现是因为不同的因素可以根据其位置以不同的方式影响结果。
空间格局的类型
在很大程度上, 我们已经讨论了点分布。 其他类型的空间数据(例如直线和多边形)又如何呢? 以下是可以在这些类型的数据中找到的一些空间关系。
邻近
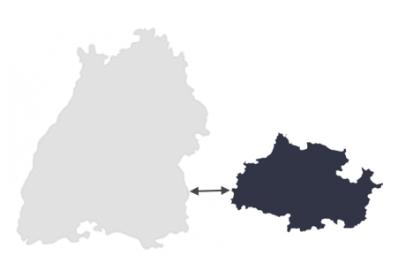
最后,距离足够近, 无需身体接触即可建立联系。 例如,两所学校相距不到一英里, 彼此很近。他们距离很近, 可以在活动上进行协作, 而无需隔邻。
邻接
邻接是指两个多边形实体直接连接共享边界。 想想两个共享边界的邻国。
重叠
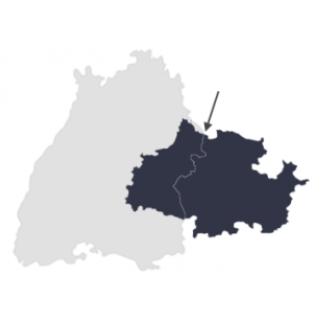
当单个实体与另一个实体共享相同位置或部分位置时, 就会发生重叠,这意味着两个或多个要素在同一空间中彼此重叠。 例如,公园可能与城市边界重叠, 既位于城市之内,又位于城市之外。
连续性
连续性是两个或多个实体共享边时之间的关系。 当区域彼此相邻并共享一侧时, 我们会发现这种空间关系。
空间模式向我们展示了世界上事物是如何相互联系的。 借助 GIS 技术, 我们能够可视化和分析空间模式。
本文内容来源于网站:https://gisgeography.com/spatial-patterns/, 由小编整理编译。
本文链接 :地理和 GIS 中的空间模式