数据图的类型以及如何在 Python 中创建和自定义
访问量: 993 次浏览
创建数据图是探索性数据分析的重要步骤。 了解在每种特定情况下构建哪种类型的数据可视化可以帮助我们从数据中提取有价值的、有时是意想不到的见解, 以做出重要的数据驱动决策。
在本文中, 我们将概述各种类型的数据图, 从最常见的到非常奇特的。 我们将了解这些数据可视化实际显示的内容、何时使用它们、何时避免它们、如何在 Python 中创建每个数据可视化的基本实例, 以及在每种类型的数据图中可以进一步自定义哪些内容以充分利用它们从中获得价值。
下载主要库和示例数据
为了获得一些数据来练习绘图, 我们首先下载必要的 Python 库和 Seaborn 库的一些内置数据集:
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
penguins = sns.load_dataset('penguins')
flights = sns.load_dataset('flights')
titanic = sns.load_dataset('titanic')
car_crashes = sns.load_dataset('car_crashes')
fmri = sns.load_dataset('fmri')
diamonds = sns.load_dataset('diamonds')
对于每种类型的数据图, 我们将创建其基本示例, 进行最少甚至无需自定义, 只是为了演示每种方法的工作原理。 不过,我们将为每个图添加相应的标题, 以使其看起来更有意义。 对于许多示例, 我们需要事先对数据进行预处理(在代码中注释为 # Data Preparation)。
常见的数据图类型
让我们从最常见的数据图开始, 它们广泛应用于许多领域, 并且可以在大多数 Python 数据可视化库中构建(除了一些非常专业的库)。
条形图
条形图是最常见的数据可视化, 用于显示分类数据的数值以比较它们之间的各种类别。 类别由相同宽度的矩形条表示, 其高度(对于垂直条形图)或长度(对于水平条形图)与它们对应的数值成比例。
要在 matplotlib 中创建基本条形图, 我们使用该 matplotlib.pyplot.bar() 函数,如下所示:
# Data preparation
penguins_grouped = penguins[['species', 'bill_length_mm']].groupby('species').mean().reset_index()
# Creating a bar chart
plt.bar(penguins_grouped['species'], penguins_grouped['bill_length_mm'])
plt.title('Average penguin bill length by species')
plt.show()
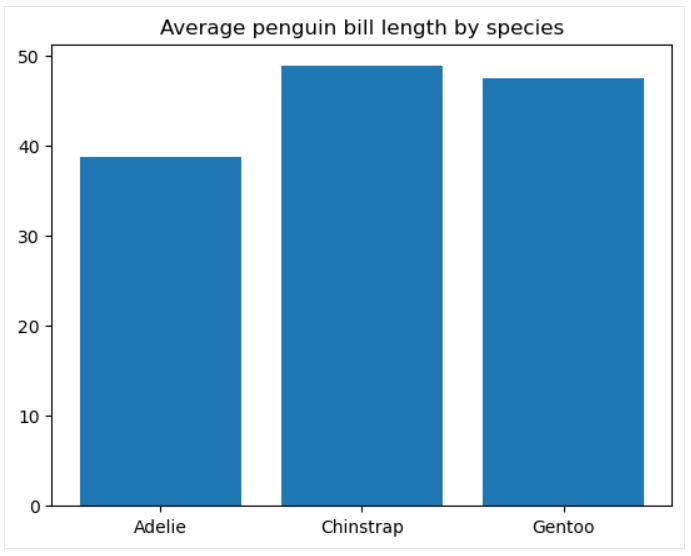
可以进一步自定义条形宽度和颜色、条形边缘宽度和颜色、向条形添加刻度标签、用图案填充条形等。
线图
线图是一种数据图表, 显示变量沿 x 轴通过由直线段连接的数据点从左到右的变化过程。 最典型的是, 随着时间的推移绘制变量的变化。 事实上,线图通常用于可视化时间序列, 如Matplotlib 时间序列线图教程中所述。
可使用该 matplotlib.pyplot.plot() 函数在 matplotlib 中创建基本的线图, 如下所示:
# Data preparation
flights_grouped = flights[['year', 'passengers']].astype({'year': 'string'}).groupby('year').sum().reset_index()
# Creating a line plot
plt.plot(flights_grouped['year'], flights_grouped['passengers'])
plt.title('Total number of passengers by year')
plt.show()
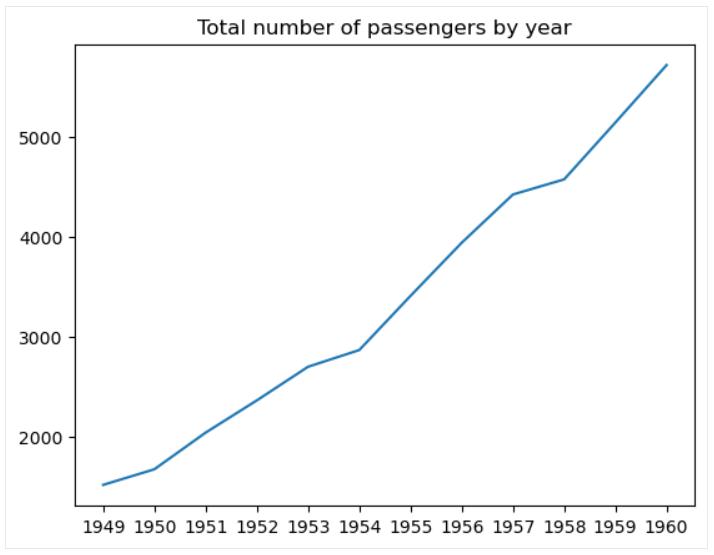
可以调整线宽、样式、颜色和透明度,添加和自定义标记等。
散点图
散点图是一种数据可视化类型, 显示在坐标平面上绘制为数据点的两个变量之间的关系。 此类数据图用于检查两个变量之间是否相关、这种相关性有多强以及数据中是否存在不同的聚类。
下面的代码说明了如何使用该函数在 matplotlib 中创建基本散点图 matplotlib.pyplot.scatter():
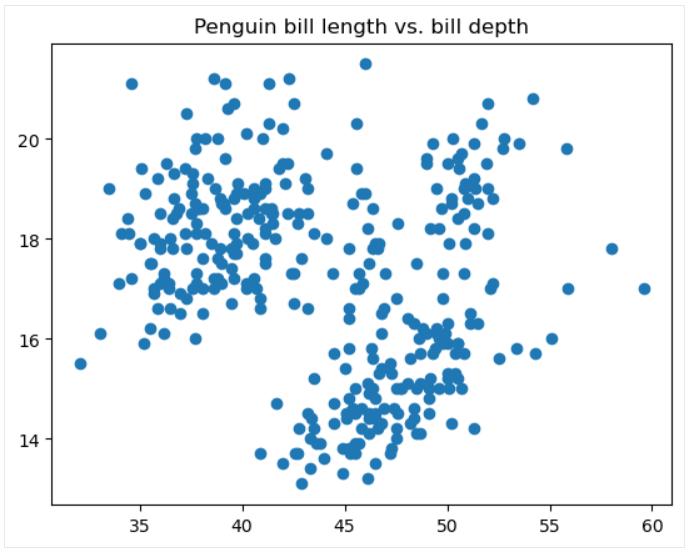
可以调整点的大小、样式、颜色、透明度、边缘宽度、边缘颜色等。
直方图
直方图是一种数据图, 表示数值变量值的频率分布。 在底层,它将数据分成称为 bin 的值范围组, 计算与每个 bin 相关的点数, 并将每个 bin 显示为垂直条, 其高度与该 bin 的计数值成比例。 直方图可以被视为一种特定类型的条形图, 只是考虑到箱的连续性质, 它的相邻条形没有间隙地连接。
可使用以下函数轻松在 matplotlib 中构建基本直方图 matplotlib.pyplot.hist():
# Creating a histogram
plt.hist(penguins['bill_length_mm'])
plt.title('Penguin bill length distribution')
plt.show()
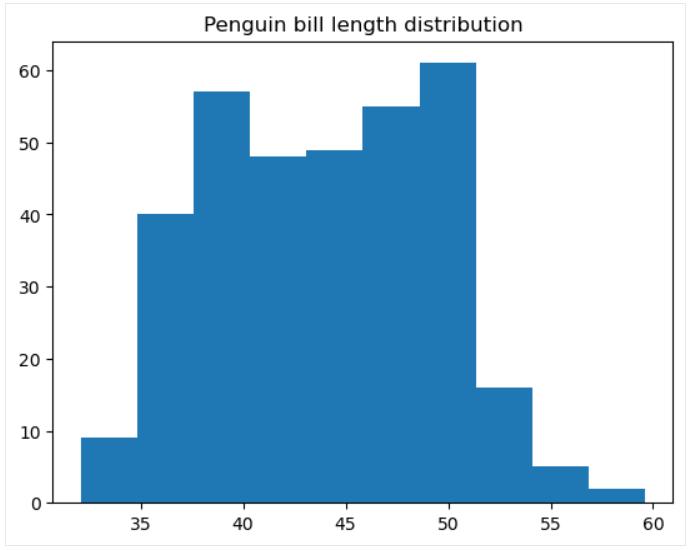
可以在该函数中自定义许多内容, 包括直方图颜色和样式、箱数、箱边缘、箱的下限和上限范围、直方图是规则的还是累积的等。
箱线图
箱线图是一种数据绘图类型, 显示一组五个数据描述性统计数据: 最小值和最大值(不包括异常值)、中位数以及第一和第三四分位数。 或者,它也可以显示平均值。 如果只对这些统计数据感兴趣, 而不深入了解真正的基础数据分布, 则箱线图是正确的选择。
可使用该函数在 matplotlib 中创建基本的箱线图 matplotlib.pyplot.boxpot(), 如下所示:
# Data preparation
penguins_cleaned = penguins.dropna()
# Creating a box plot
plt.boxplot(penguins_cleaned['bill_length_mm'])
plt.title('Penguin bill length distribution')
plt.show()
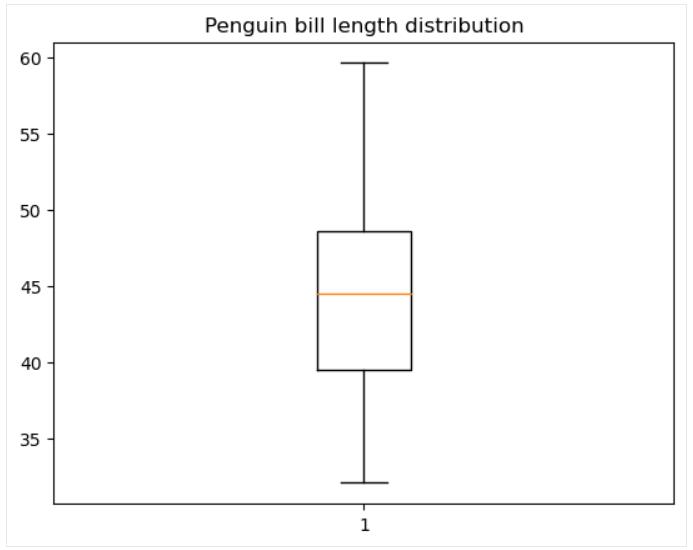
有足够的空间来自定义箱线图:箱线宽度和方向、箱线和须线位置、各种箱线图元素的可见性和样式等。
请注意, 要使用此函数创建箱形图, 首先需要确保数据不包含缺失值。 事实上,在上面的示例中, 在绘图之前删除了数据中的缺失值。 作为比较,Seaborn 库没有此限制, 并在幕后处理缺失值, 如下所示:
# Creating a box plot
sns.boxplot(data=penguins, y='bill_length_mm')
plt.title('Penguin bill length distribution')
plt.show()
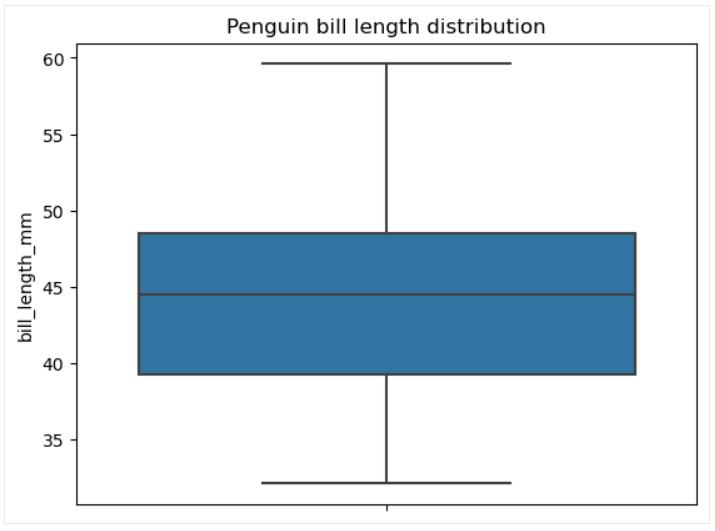
饼形图
饼形图是一种数据可视化的类型, 由分成多个扇区的圆表示, 其中每个扇区对应于分类数据的某个类别, 每个扇区的角度反映了该类别作为整体的一部分的比例。 与条形图不同, 饼图应该描述构成整体的类别, 例如船上的乘客。
饼图有一些缺点:
- 对于人眼来说,角度比长度更难以解释,而且常常会产生误导。
- 在五个或更多类别的情况下,它们的效率较低。
- 它们无法显示多于一组的分类数据。换句话说,与条形图不同,它们无法分组。
- 他们不容易揭示真正的价值观。
- 当涉及到其值差异较小的类别时,它们并不能提供足够的信息。
- 因此,应谨慎使用饼图。
要在 matplotlib 中创建基本饼图, 需要应用该 matplotlib.pyplot.pie() 函数, 如下所示:
# Data preparation
titanic_grouped = titanic.groupby('class')['pclass'].count().reset_index()
# Creating a pie chart
plt.pie(titanic_grouped['pclass'], labels=titanic_grouped['class'])
plt.title('Number of passengers by class')
plt.show()
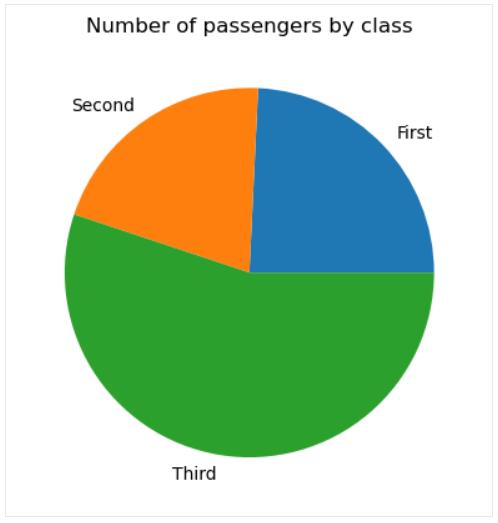
如有必要, 可以调整饼形图:更改其楔形的颜色, 为某些楔形(通常非常小的楔形)添加偏移量, 更改圆半径,自定义标签格式, 用图案填充部分或所有楔形等。
数据图的高级类型
在本节中,我们将探索各种高级数据图。 其中一些代表了我们在上一节中考虑的常见数据可视化类型的奇特变体, 其他只是独立类型。
分组条形图
常见的条形图用于按类别显示分类变量的数值, 而分组条形图则具有相同的目的, 但跨两个分类变量。 从图形上看, 这意味着有几组条形图, 每组与一个变量的特定类别相关, 这些组中的每个条形图与第二个变量的特定类别相关。 当第二个变量的类别不超过三个时, 分组条形图效果最佳。 在相反的情况下, 它们会变得过于拥挤, 因此帮助不大。
与常见的条形图一样, 可以使用 matplotlib 创建分组条形图。 然而,Seaborn 库提供了更方便的功能 seaborn.barplot() 来创建此类绘图。 让我们看一个为企鹅喙长度创建基本分组条形图的示例, 涉及两个类别变量:物种和性别。
# Creating a grouped bar chart
sns.barplot(data=penguins, x='species', y='bill_length_mm', hue='sex')
plt.title('Penguin bill length by species and sex')
plt.show()
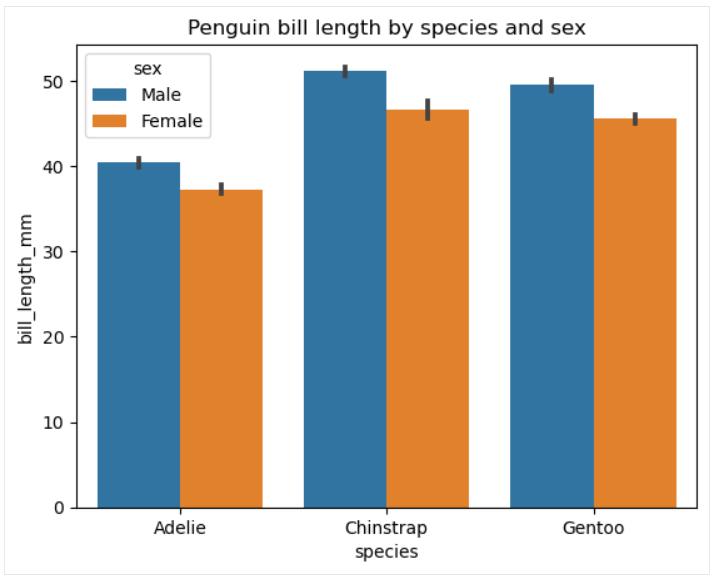
第二个分类变量是通过色调参数引入的。该函数的其他可选参数允许更改条形方向、宽度和颜色、类别顺序、统计估计器等。
堆积面积图
堆叠面积图是公共面积图的扩展(它只是一个线图,线下方的区域着色或填充有图案), 具有多个区域, 每个区域对应一个特定变量, 彼此堆叠。 当需要跟踪一组变量的总体进度以及每个变量对此进度的单独贡献时, 此类图表非常有用。 与线图一样, 堆积面积图通常反映变量随时间的变化。
重要的是要记住堆积面积图的主要局限性:它们主要帮助捕获总体趋势, 但不能捕获堆积面积的确切值。
为了在 matplotlib 中构建基本的堆积面积图, 使用该 matplotlib.pyplot.stackplot 函数, 如下所示:
# Data preparation
flights_grouped = flights.groupby(['year', 'month']).mean().reset_index()
flights_49_50 = pd.DataFrame(list(zip(flights_grouped.loc[:11, 'month'].tolist(), flights_grouped.loc[:11, 'passengers'].tolist(), flights_grouped.loc[12:23, 'passengers'].tolist())), columns=['month', '1949', '1950'])
# Creating a stacked area chart
plt.stackplot(flights_49_50['month'], flights_49_50['1949'], flights_49_50['1950'], labels=['1949', '1950'])
plt.title('Number of passengers in 1949 and 1950 by month')
plt.legend()
plt.show()
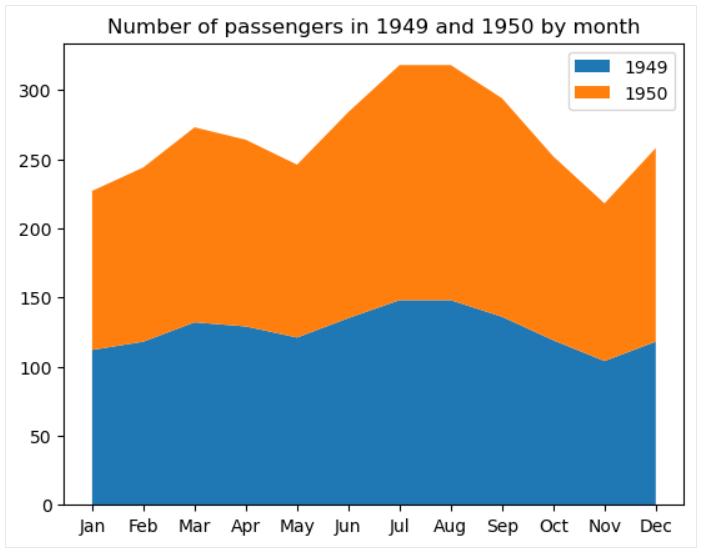
此类图表的一些可自定义属性包括区域颜色、透明度、填充图案、线宽、样式、颜色、透明度等。
多箱线图
在数据图的常见类型部分中, 我们将 box-pot 定义为一种数据可视化类型, 它显示一组五个数据描述性统计数据。 有时,可能希望针对分类变量的每个类别分别显示和比较这些统计数据。 在这种情况下, 需要在同一绘图区域上绘制多个框, 可以使用该函数轻松完成此 seaborn.boxplot() 操作, 如下所示:
# Creating multiple box plots
sns.boxplot(data=penguins, x='bill_length_mm', y='species')
plt.title('Penguin bill length distribution by species')
plt.show()
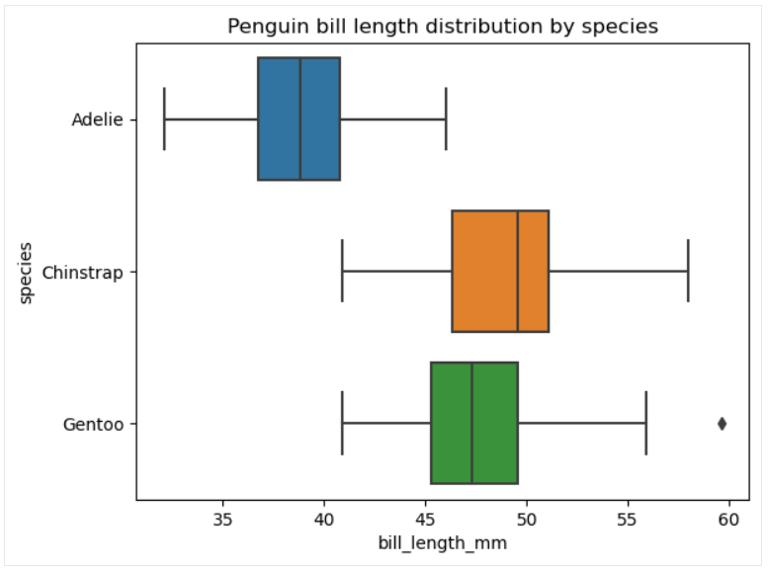
可以更改箱线图的顺序、方向、颜色、透明度、宽度、各种元素的属性、在绘图区域添加另一个分类变量等。
小提琴图表
小提琴图与箱线图类似, 显示相同的数据总体统计信息, 但它还显示该数据的分布形状。 与箱线图一样, 我们可以为感兴趣的数据创建单个小提琴图, 或者更常见的是, 创建多个小提琴图, 每个小提琴图对应一个分类变量的单独类别。
Seaborn 比 matplotlib 提供了更多创建和自定义小提琴图的空间。 要在 seaborn 中构建基本的小提琴图, 需要应用该 seaborn.violinplot() 函数, 如下所示:
Creating a violin plot
sns.violinplot(data=penguins, x='bill_length_mm', y='species')
plt.title('Penguin bill length distribution by species')
plt.show()
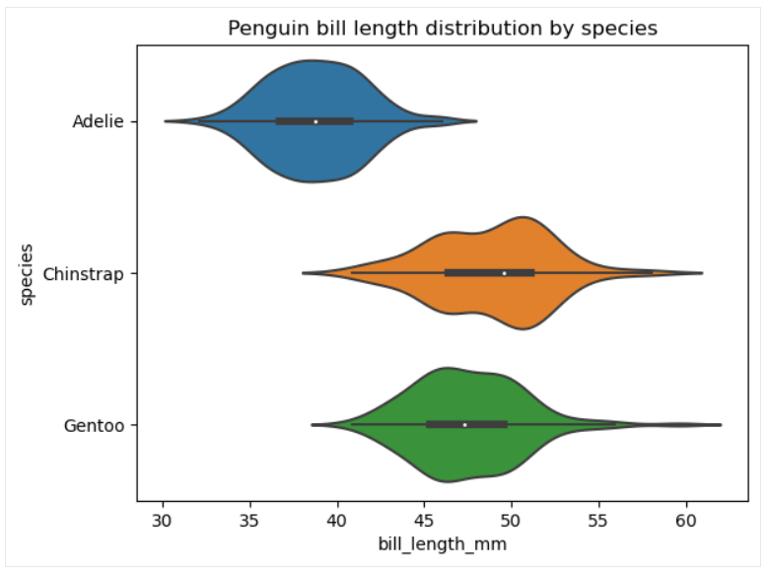
可以修改小提琴的顺序、它们的方向、颜色、透明度、宽度、各种元素的属性, 将分布扩展到极端数据点以上, 在绘图区域上添加另一个分类变量, 选择数据点的方式体现在小提琴内饰等方面。
热图
热图是一种表格样式的数据可视化类型, 其中每个数值数据点都是根据选定的色标并根据数据集中数据点的大小来描述的。 这些图背后的主要思想是说明可能需要特别注意的数据的潜在热点和冷点。
在许多情况下, 数据在为其创建热图之前需要进行一些预处理, 这通常意味着数据清理和标准化。
下面的代码显示了如何使用该 seaborn.heatmap() 函数创建基本热图(在必要的数据预处理之后):
# Data preparation
from sklearn import preprocessing
car_crashes_cleaned = car_crashes.drop(labels='abbrev', axis=1).iloc[0:10]
min_max_scaler = preprocessing.MinMaxScaler()
car_crashes_normalized = pd.DataFrame(min_max_scaler.fit_transform(car_crashes_cleaned.values), columns=car_crashes_cleaned.columns)
# Creating a heatmap
sns.heatmap(car_crashes_normalized, annot=True)
plt.title('Car crash heatmap for the first 10 car crashes')
plt.show()
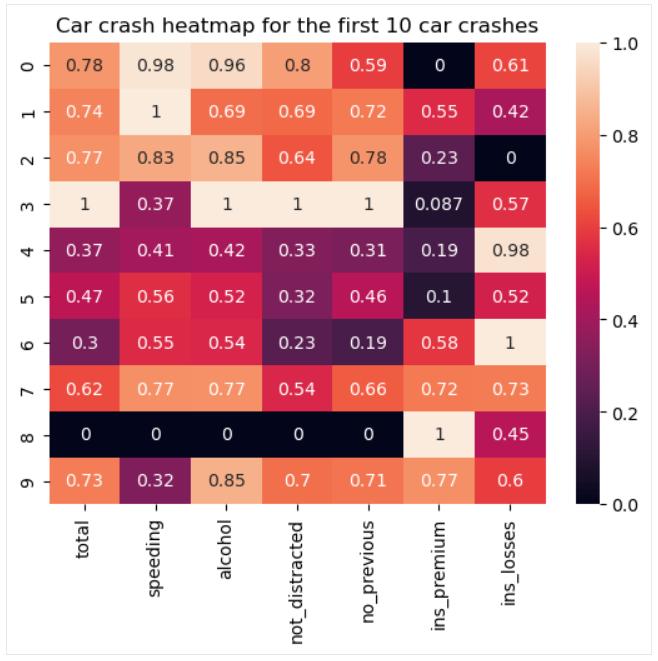
一些可能的调整可能包括选择颜色图、定义锚定值、格式化注释、自定义分隔线、应用蒙版等。
非常规类型的数据图
最后,让我们看一下一些很少使用甚至鲜为人知的数据可视化类型。 其中许多在更流行的图表类型中至少有一种类似物。 然而,在某些特定情况下, 这些非常规的数据可视化可以比常用的绘图更有效。
分布茎叶图
分布茎叶图实际上是表示条形图的另一种方式, 只不过它不是实心条形图, 而是由细线组成,每个细线顶部都有(可选)标记。虽然干图可能看起来是条形图的冗余变体,但在可视化许多类别时,它实际上是更好的选择。与条形图相比,茎图的优点在于它们具有改进的数据墨水比率,因此增强了可读性。
要在 matplotlib 中创建基本的茎图, 我们使用该 matplotlib.pyplot.stem() 函数, 如下所示:
# Data preparation
fmri_grouped = fmri.groupby('subject')[['subject', 'signal']].max()
# Creating a stem plot
plt.stem(fmri_grouped['subject'], fmri_grouped['signal'])
plt.title('FMRI maximum signal by subject')
plt.show()
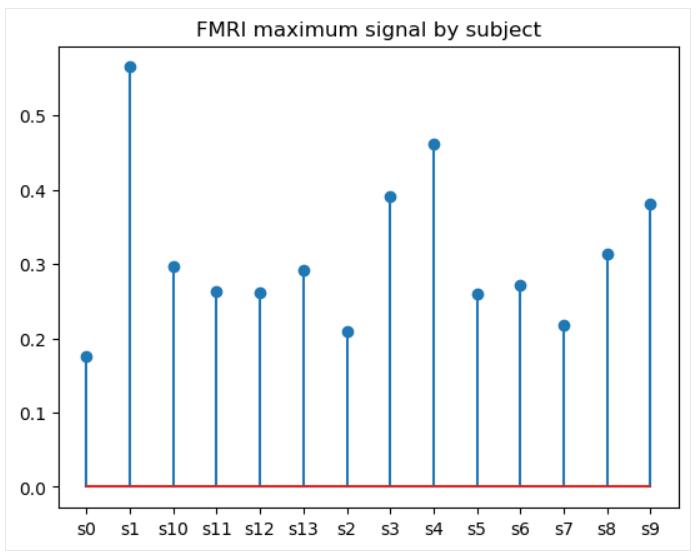
我们可以使用该函数的可选参数来更改词干方向并自定义词干、基线和标记属性。
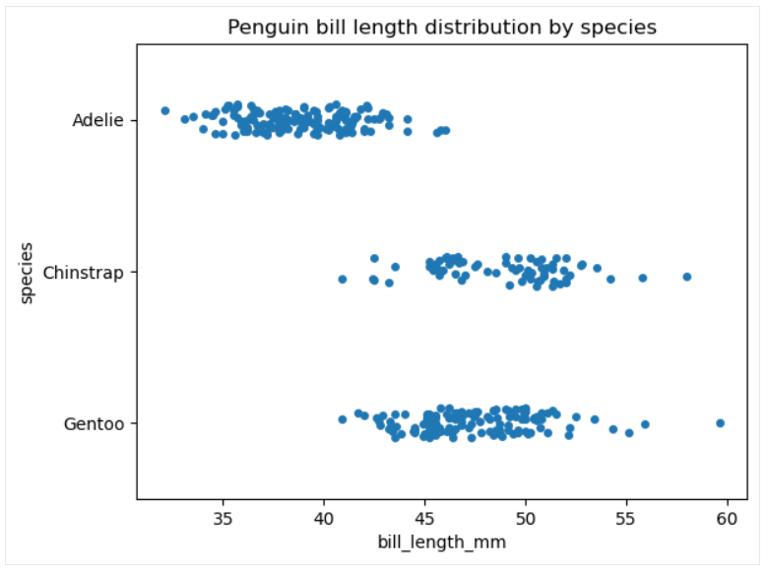
带状图和群图
这两种非常相似的数据可视化类型可以被视为分类变量散点图的实现:带状图和群图都显示数据分布的内部, 包括样本大小和各个数据点的位置, 但不包括描述性统计。 这些图之间的主要区别在于, 在带状图中, 数据点可以重叠, 而在群图中则不能。 相反,在群图中, 数据点沿分类轴对齐。 带状图和群图仅对相对较小的数据集有帮助。
以下是我们如何使用该函数创建带状图 seaborn.stripplot(): 可以使用该函数的可选参数来更改词干方向并自定义词干、基线和标记属性。
# Creating a strip plot
sns.stripplot(data=penguins, x='bill_length_mm', y='species')
plt.title('Penguin bill length distribution by species')
plt.show()
现在,让我们使用 seaborn.swarmplot() 相同数据的函数创建一个群图并观察差异:
# Creating a swarm plot
sns.swarmplot(data=penguins, x='bill_length_mm', y='species')
plt.title('Penguin bill length distribution by species')
plt.show()
和函数具有非常 seaborn.stripplot() 相似 seaborn.swarmplot() 的语法。 这两个函数中的一些可自定义属性是绘图顺序和方向以及标记属性, 例如标记样式、大小、颜色、透明度等。 值得一提的是, 调节标记透明度有助于部分解决带状图中的点重叠问题。
树状图
树状图是一种数据图, 用于将分类数据的数值按类别可视化为放置在矩形框架内的一组矩形, 每个矩形的面积与相应类别的值成比例。 就其用途而言, 树形图与条形图和饼图相同。 与饼图一样, 它们主要应该描述构成整体的类别。 当多达十个类别的数值存在明显差异时, 树状图看起来会有效且引人注目。
树状图的缺点与饼图的缺点非常相似:
- 对于人眼来说,面积比长度更难以解释,并且常常会产生误导。
- 在超过十个类别的情况下,它们的效率较低。
- 它们无法显示多于一组的分类数据。换句话说,与条形图不同,它们无法分组。
- 他们不容易揭示真正的价值观。
- 当涉及到其值差异较小的类别时,它们并不能提供足够的信息。
我们应该牢记这些要点, 并谨慎使用树状图, 并且仅在它们效果最佳时才使用它们。
要在 Python 中构建树状图, 首先需要安装并导入 squarify 库:pip install squarify, 然后是 import squarify 。 下面的代码创建一个基本的树状图:
import squarify
# Data preparation
diamonds_grouped = diamonds[['cut', 'price']].groupby('cut').mean().reset_index()
# Creating a treemap
squarify.plot(sizes=diamonds_grouped['price'], label=diamonds_grouped['cut'])
plt.title('Average diamond price by cut')
plt.show()
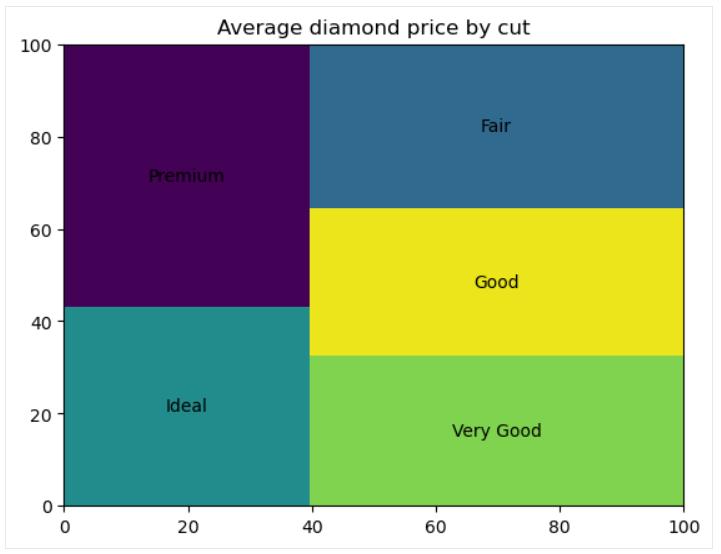
可以自定义矩形的颜色和透明度, 用图案来填充,调整矩形边缘属性, 在矩形之间添加小间隙, 以及调整标签文本属性。
还有另一种在 Python 中创建树形图的方法, 使用 plotly 库。
Word cloud(词云)
词云是一种文本数据可视化类型, 其中每个单词的字体大小对应于其在输入文本中出现的频率。 使用词云有助于找到一段文本中最重要的单词。
虽然词云对于任何类型的目标受众来说总是引人注目且直观易懂, 但我们应该意识到此类数据图的一些内在局限性:
- 创建词云通常需要大量耗时的数据准备。
- 与大多数文本挖掘工具一样, 词云缺乏上下文,很容易产生误解。 例如,它们不会捕捉文本中的讽刺、否定或不字面意思。
- 不允许明确的单词排名。 这意味着我们可以轻松区分最常见的单词, 第二个,第三个,也许第四个, 那么一切就变得不那么容易了。
- 没有揭示词频的精确值。
- 它们创造了一种视觉错觉, 即相同频率下较长的单词看起来比较短的单词更大。 拥有许多垂直文字或应用遮罩会降低图表的可读性。
词云的一个有趣且鲜为人知的应用是, 可以不根据词频而是根据分配给每个词的任何其他属性来制作它们。 例如,可以创建一个国家/地区字典, 为每个国家/地区分配其人口值, 并显示该数据。
要在Python中创建词云, 需要使用专门的词云库。 首先,需要安装它(pip install wordcloud), 然后导入 WordCloud 类和停用词:from wordcloud import WordCloud,STOPWORDS。 以下代码生成一个基本的词云:
from wordcloud import WordCloud, STOPWORDS
text = 'cat cat cat cat cat cat dog dog dog dog dog panda panda panda panda koala koala koala rabbit rabbit fox'
# Creating a word cloud
wordcloud = WordCloud().generate(text)
plt.imshow(wordcloud)
plt.title('Words by their frequency in the text')
plt.axis('off')
plt.show()

可以调整词云的尺寸, 更改其背景颜色, 分配用于显示单词的颜色图, 将首选项设置为水平单词而不是垂直单词, 限制显示单词的最大数量, 更新停用词列表, 限制字体大小, 考虑单词搭配, 确保图形的可重复性等。
结论
在本文中,我们讨论了几种类型的数据图、它们的使用领域、局限性以及如何在 Python 中构建和自定义它们。 我们从最常见的数据可视化开始, 然后是更高级的数据可视化, 最后是一些非常规但有时非常有用的数据图类型。 希望对大家有所帮助。