Pandas dataframe.ffill () 用法详解与实例教程
访问量: 10 次浏览
Python Pandas dataframe.ffill()
Python是一种进行数据分析的伟大语言,主要是因为以数据为中心的Python软件包的奇妙生态系统。
Pandas
就是这些包中的一个,它使导入和分析数据更加容易。
Pandas
dataframe.fill() 函数被用来填补数据框架中的缺失值。ffill "代表 "向前填充",将向前传播最后一个有效的观察值。
语法:
DataFrame.ffill(axis=None, inplace=False, limit=None, downcast=None)
参数:
axis:
{0,索引1,列}。
inplace :
如果为真,就地填充。注意:这将修改这个对象上的任何其他视图,(例如,在 DataFrame 中的一个列的无复制切片)。
limit :
如果指定了方法,这就是向前/向后填充连续NaN值的最大数量。换句话说,如果有一个缺口的连续NaN值超过这个数量,它将只被部分填补。如果没有指定方法,这是沿整个 axis 的最大条目数,其中NaN将被填充。如果不是无,必须大于0。
Downcast:
item->dtype的一个dict,如果可能的话,要进行下转换,或者字符串'infer',它将尝试下转换到一个适当的等价类型(例如,如果可能的话,float64到int64)。
返回 :
filled : DataFrame
示例#1:
使用fill()函数沿索引axis填充缺失的数值。
注意:
当fill()被应用于整个索引时,那么任何缺失的值都会根据前一行的相应值来填补。
# importing pandas as pd
import pandas as pd
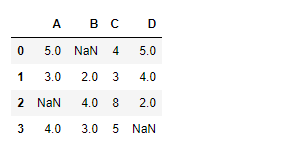
# Creating the dataframe
df=pd.DataFrame({"A":[5,3,None,4],
"B":[None,2,4,3],
"C":[4,3,8,5],
"D":[5,4,2,None]})
# Print the dataframe
df
 ")
")
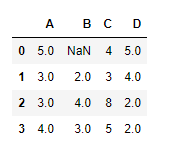
让我们在索引axis上填补缺失的值
# applying ffill() method to fill the missing values
df.ffill(axis = 0)
输出 :
 ")
")
注意,第一行的值仍然是NaN值,因为上面没有可以传播非NA值的行。
示例#2:
使用fill()函数沿列axis填充缺失的数值。
注意:
当fill被应用于整个列axis时,那么缺失的值会被同一行的前一列的值所填补。
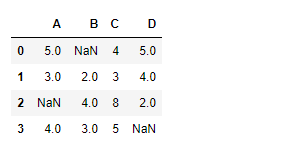
# importing pandas as pd
import pandas as pd
# Creating the dataframe
df=pd.DataFrame({"A":[5,3,None,4],
"B":[None,2,4,3],
"C":[4,3,8,5],
"D":[5,4,2,None]})
# Print the dataframe
df
 ")
")
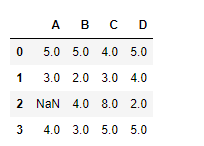
让我们在列axis上填补缺失的值
# applying ffill() method to fill the missing values
df.ffill(axis = 1)
输出 :
 ")
")
注意,第一列的值是NaN值,因为没有单元格留给它,所以这个单元格不能用前面的单元格值沿列axis填充。