Pandas DataFrame 把文本列分割成两列的两种方法详解
发布日期 : 2022-08-24 16:55:08 UTC
访问量: 10 次浏览
让我们看看如何在 Pandas DataFrame中把一个文本列分成两列。
方法 #1: 使用 Series.str.split() 函数。
将名字列分成两个不同的列。默认情况下,通过 str.split() 函数在单个空格的基础上进行分割。
# import Pandas as pd
import pandas as pd
# create a new data frame
df = pd.DataFrame({'Name': ['John Larter', 'Robert Junior', 'Jonny Depp'],
'Age':[32, 34, 36]})
print("Given Dataframe is :\n",df)
# bydefault splitting is done on the basis of single space.
print("\nSplitting 'Name' column into two different columns :\n",
df.Name.str.split(expand=True))
输出:
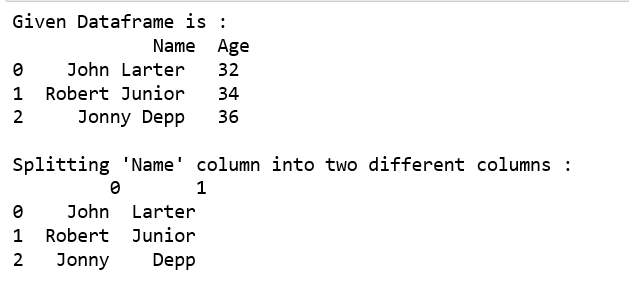
将姓名列分别拆分为 "First" 和 "Last" 列,并将其添加到现有的数据框架中。
# import Pandas as pd
import pandas as pd
# create a new data frame
df = pd.DataFrame({'Name': ['John Larter', 'Robert Junior', 'Jonny Depp'],
'Age':[32, 34, 36]})
print("Given Dataframe is :\n",df)
# Adding two new columns to the existing dataframe.
# bydefault splitting is done on the basis of single space.
df[['First','Last']] = df.Name.str.split(expand=True)
print("\n After adding two new columns : \n", df)
输出:
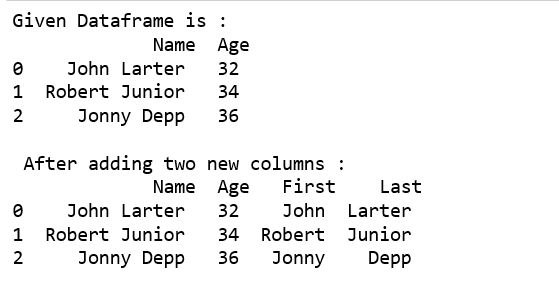
使用下划线作为分隔符,将该列分成两列。
# import Pandas as pd
import pandas as pd
# create a new data frame
df = pd.DataFrame({'Name': ['John_Larter', 'Robert_Junior', 'Jonny_Depp'],
'Age':[32, 34, 36]})
print("Given Dataframe is :\n",df)
# Adding two new columns to the existing dataframe.
# splitting is done on the basis of underscore.
df[['First','Last']] = df.Name.str.split("_",expand=True)
print("\n After adding two new columns : \n",df)
输出:
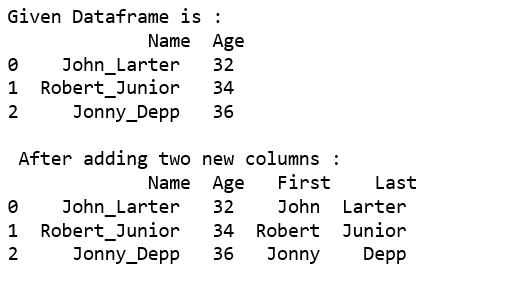
一起使用 str.split()、tolist() 函数。
# import Pandas as pd
import pandas as pd
# create a new data frame
df = pd.DataFrame({'Name': ['John_Larter', 'Robert_Junior', 'Jonny_Depp'],
'Age':[32, 34, 36]})
print("Given Dataframe is :\n",df)
print("\nSplitting Name column into two different columns :")
print(pd.DataFrame(df.Name.str.split('_',1).tolist(),
columns = ['first','Last']))
输出:
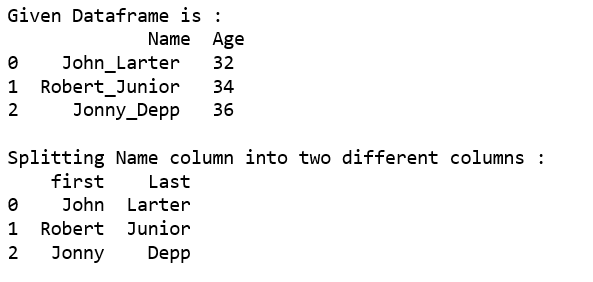
方法 #2: 使用 apply() 函数。
将 "Name" 列分成两个不同的列。
# import Pandas as pd
import pandas as pd
# create a new data frame
df = pd.DataFrame({'Name': ['John_Larter', 'Robert_Junior', 'Jonny_Depp'],
'Age':[32, 34, 36]})
print("Given Dataframe is :\n",df)
print("\nSplitting Name column into two different columns :")
print(df.Name.apply(lambda x: pd.Series(str(x).split("_"))))
输出:

将 "Name" 列分成两个不同的列,分别命名为 "First" 和 "Last",然后将其添加到现有数据框架中。
# import Pandas as pd
import pandas as pd
# create a new data frame
df = pd.DataFrame({'Name': ['John_Larter', 'Robert_Junior', 'Jonny_Depp'],
'Age':[32, 34, 36]})
print("Given Dataframe is :\n",df)
print("\nSplitting Name column into two different columns :")
# splitting 'Name' column into Two columns
# i.e. 'First' and 'Last'respectively and
# Adding these columns to the existing dataframe.
df[['First','Last']] = df.Name.apply(
lambda x: pd.Series(str(x).split("_")))
print(df)
输出:
