

将模型与N维数据并行进行匹配#
在某些情况下,您可能希望将模型多次与数据匹配。例如,您可能有一个光谱立方体(具有两个天轴和一个光谱轴),并且您想要将1D模型(可以是简单的高斯模型,也可以是具有多条线和连续体的复杂复合模型)与立方体中的每个单独光谱相匹配。或者,您可能有一个具有两个天轴、一个光谱轴和一个时间轴的立方体,并且您想要将2D模型适合立方体中的每个2D天面。如果每个模型匹配都可以被视为独立的,那么并行执行这些模型匹配就会带来显着的性能好处。
The parallel_fit_dask() function is ideally
suited to these use cases. It makes it simple to set up fitting of M-dimensional
models to N-dimensional datasets and leverages the power of the dask package to efficiently parallelize the problem,
running it either on multiple processes of a single machine or in a distributed
environment. You do not need to know how to use dask in order to use this function,
but you will need to make sure you have dask
installed.
请注意,这里的方法与 model sets 所述之 拟合模型集 ,这是一种将具有参数载体的线性模型匹配到数据数组的方法,因为在该特定情况下,该匹配可以真正被载体化,并且可能不会受益于这里描述的方法。
入门#
为了演示该功能的使用,我们将通过一个将1D模型匹配到小光谱立方体的简单示例(如果您有兴趣访问该文件,可以在 l1448_13co.fits ,但下面的代码会自动下载)。
我们首先下载多维数据集并提取数据和LCS:
>>> from astropy.wcs import WCS
>>> from astropy.io import fits
>>> from astropy.utils.data import get_pkg_data_filename
>>> filename = get_pkg_data_filename('l1448/l1448_13co.fits')
>>> with fits.open(filename) as hdulist:
... data = hdulist[0].data
... wcs = WCS(hdulist[0].header)
我们在空间上提取一个子立方体以供演示:
>>> data = data[:, 25:75, 35:85]
>>> wcs = wcs[:, 25:75, 35:85]
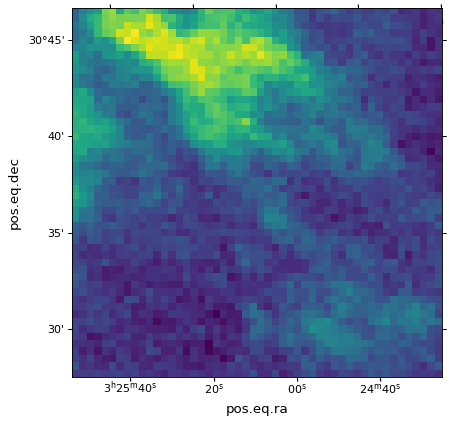
这是一个由13 CO线追踪的恒星形成区域的立方体。我们可以看看其中一个频道:
>>> import matplotlib.pyplot as plt
>>> fig, ax = plt.subplots(subplot_kw=dict(projection=wcs, slices=('x', 'y', 20)))
>>> ax.imshow(data[20, :, :])
{kind=link}
{kind=link}
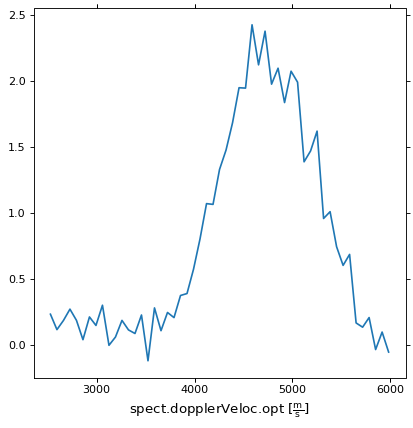
我们还可以提取其中一个天体位置的光谱:
>>> fig, ax = plt.subplots(subplot_kw=dict(projection=wcs, slices=(5, 5, 'x')))
>>> ax.plot(data[:, 5, 5])
{kind=link}
{kind=link}
我们现在建立一个模型来适应这一点;我们将使用一个简单的高斯模型,并对参数进行一些合理的初始猜测:
>>> from astropy import units as u
>>> from astropy.modeling.models import Gaussian1D
>>> model = Gaussian1D(amplitude=1 * u.one, mean=4000 * u.m / u.s, stddev=500 * u.m / u.s)
在这种情况下,数据没有任何单位,因此我们使用 u.one 作为单位,这表明它是无量纲的。
在将其匹配到立方体中的所有光谱之前,最好使用至少一个光谱手动测试模型。为此,我们需要提取光谱的x轴:
>>> import numpy as np
>>> x = wcs.pixel_to_world(0, 0, np.arange(data.shape[0]))[1]
>>> x
<SpectralCoord
(target: <ICRS Coordinate: (ra, dec, distance) in (deg, deg, kpc)
(57.66, 0., 1000.)
(pm_ra_cosdec, pm_dec, radial_velocity) in (mas / yr, mas / yr, km / s)
(0., 0., 0.)>)
[2528.19489695, 2594.61850695, 2661.04211695, 2727.46572695,
2793.88933695, 2860.31294695, 2926.73655695, 2993.16016695,
...
5716.52817695, 5782.95178695, 5849.37539695, 5915.79900695,
5982.22261695] m / s>
我们现在可以进行匹配:
>>> from astropy.modeling.fitting import TRFLSQFitter
>>> fitter = TRFLSQFitter()
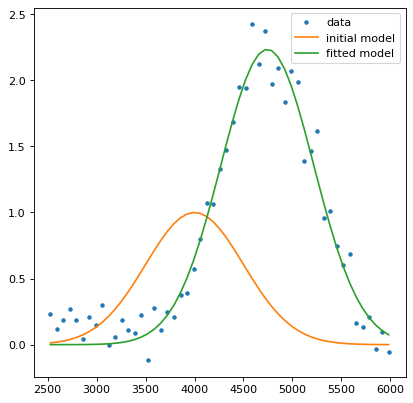
>>> model_fit_single = fitter(model, x, data[:, 5, 5])
>>> fig, ax = plt.subplots()
>>> ax.plot(x, data[:, 5, 5], '.', label='data')
>>> ax.plot(x, model(x), label='initial model')
>>> ax.plot(x, model_fit_single(x), label='fitted model')
>>> ax.legend()
{kind=link}
{kind=link}
该模型似乎有效!我们现在可以使用 parallel_fit_dask() 用于适应立方体中所有光谱的函数:
>>> from astropy.modeling.fitting import parallel_fit_dask
>>> model_fit = parallel_fit_dask(model=model,
... fitter=fitter,
... data=data,
... world=wcs,
... fitting_axes=0,
... data_unit=u.one,
... scheduler='synchronous')
本案的论点如下:
model=是初始模型。虽然在我们的例子中,初始参数被指定为纯量,但如果您希望具有不同的初始参数作为数据集中位置的函数,则可以传递具有数组参数的模型。fitter=是最合适的例子data=是N维数据集,在我们的例子中是3D光谱立方体。world=提供有关配合的世界坐标的信息,例如光谱的光谱坐标。这可以通过不同的方式指定,但在上面我们选择为数据集传递LCS对象,将从中提取光谱轴坐标。fitting_axes=指定哪些轴或哪些轴包括要匹配的数据。在我们的示例中,我们正在对光谱进行匹配,在NumPy符号中,光谱是立方体中的第一个轴,因此我们指定fitting_axes=0.data_unit=指定用于数据的单位。在我们的情况下,数据没有单位,但由于我们使用光谱轴单位,因此我们需要指定u.one这里.
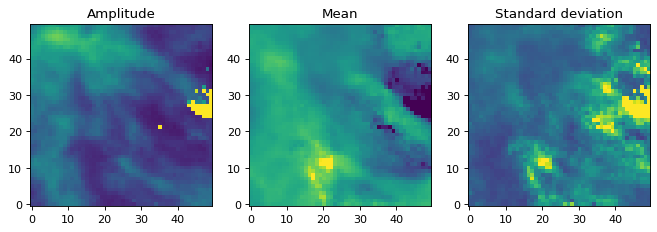
我们现在可以看看参数映射:
>>> fig, axs = plt.subplots(figsize=(10, 5), ncols=3)
>>> ax1 = axs[0]
>>> ax1.set_title('Amplitude')
>>> ax1.imshow(model_fit.amplitude.value, vmin=0, vmax=5, origin='lower')
>>> ax2 = axs[1]
>>> ax2.set_title('Mean')
>>> ax2.imshow(model_fit.mean.value, vmin=2500, vmax=6000, origin='lower')
>>> ax3 = axs[2]
>>> ax3.set_title('Standard deviation')
>>> ax3.imshow(model_fit.stddev.value, vmin=0, vmax=2000, origin='lower')
{kind=link}
{kind=link}
有许多像素似乎存在问题。检查平均值的图表,我们可以看到很多值根本不在我们正在适应的光谱范围内:
>>> fig, ax = plt.subplots()
>>> ax.hist(model_fit.mean.value.ravel(), bins=100)
>>> ax.set(yscale='log', xlabel='mean', ylabel='number')
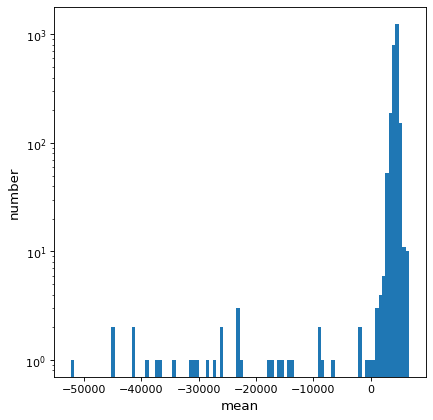{kind=link}
{kind=link}
我们可以设定平均值的界限并再次尝试适合
>>> model.mean.bounds = (3000, 6000) * u.km / u.s
>>> model_fit = parallel_fit_dask(model=model,
... fitter=fitter,
... data=data,
... world=wcs,
... fitting_axes=0,
... data_unit=u.one,
... scheduler='synchronous')
我们可以看到结果:
>>> fig, axs = plt.subplots(figsize=(10, 5), ncols=3)
>>> ax1 = axs[0]
>>> ax1.set_title('Amplitude')
>>> ax1.imshow(model_fit.amplitude.value, vmin=0, vmax=5, origin='lower')
>>> ax2 = axs[1]
>>> ax2.set_title('Mean')
>>> ax2.imshow(model_fit.mean.value, vmin=2500, vmax=6000, origin='lower')
>>> ax3 = axs[2]
>>> ax3.set_title('Standard deviation')
>>> ax3.imshow(model_fit.stddev.value, vmin=0, vmax=2000, origin='lower')
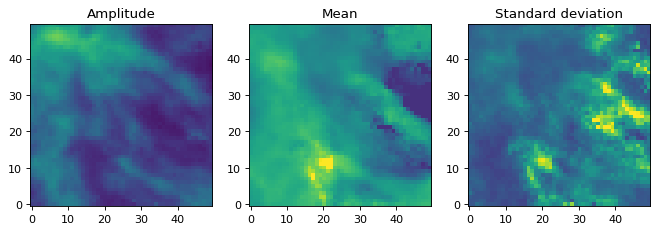{kind=link}
{kind=link}
振幅图不再包含任何有问题的像素。
世界输入#
上面的例子证明了可以传递 astropy.wcs.WCS 反对 world= 参数,以确定匹配的世界坐标(例如,光谱匹配的光谱轴值)。还可以传递一个数组的数组数组-如果您这样做,那么数组每个适配轴应该有一个项。传递1D数组的数组是最有效的,但如果世界坐标在迭代的轴上变化,则您还可以传递N-d数组的数组,给出每个单独像素的坐标(也可以传递不是1D但也不是完全N-d的数组,只要它们可以广播到数据形状)。
多处理#
默认情况下, parallel_fit_dask() 将利用多处理来并行化配件。如果您编写脚本来执行调试,您可能需要将代码移动到::
if __name__ == "__main__":
...
否则Python将多次执行脚本中的整个代码,并且可能是以循环方式执行的,而不仅仅是并行化的配件。
性能#
的 parallel_fit_dask() 函数将数据拆分为块,然后将每个块发送到不同的进程。这些块的大小对于获得良好的性能至关重要。如果我们将每个数据分割成一个块,则由于进程间通信的巨大负担,该流程将效率低下。相反,如果我们将数据分成比可用进程更少的块,那么我们将无法利用所有可用的计算能力。如果我们将数据分成比流程稍多的块,也会出现效率低下的情况。例如,将数据分成五个块,并具有四个可用的进程意味着这四个进程将首先容纳四个块,然后将保留一个进程来容纳剩余的块。因此,仔细考虑如何分割数据非常重要。
要控制数据的拆分,请使用 chunk_n_max= 关键字参数。这决定了每个块中将进行多少次个人贴合。例如,当将模型与光谱立方体中的各个光谱匹配时,设置 chunk_n_max=100 意味着每个块将包含100个光谱。作为一般指南,您可能希望将其设置为大约在数据中执行的匹配数除以可用流程数量的几倍。例如,如果您需要适应100,000个光谱并且有8个可用过程,请设置 chunk_n_max=1000 是合理的这种配置将数据分成100个块,这意味着每个进程将需要处理大约12个块。此外,每个块拟合1,000个频谱将花费足够的时间来避免被通信开销所支配。
的默认值 chunk_n_max 是500。
贴合度信息#
当使用astropy进行常规(非平行)拟合时,拟合人员通常会有一个 .fit_info 属性,包含有关配合的信息,例如函数评估的数量、参数协方差矩阵等。可用的信息取决于使用的特定配合者。
在某些情况下,这些配合信息对象可能会比最初正在配合的数据占用更多内存,因此当同时执行多次配合时 parallel_fit_dask() ,默认情况下不会保留此信息,并且 .fit_info Fitter实例上的参数设置为 None
然而,由于访问此信息在某些情况下可能很有用,因此可以选择保留它。通过设置,可以保留所有适合的信息 fit_info=True :
>>> model_fit = parallel_fit_dask(model=model,
... ...
... fitter=fitter,
... fit_info=True)
或者只是特定的键(这可以帮助减少内存使用):
>>> model_fit = parallel_fit_dask(model=model,
... ...
... fitter=fitter,
... fit_info=('nfev', 'message', 'status'))
在这种情况下, .fit_info 将被设置为 FitInfoArrayContainer 对象,它内部有一个numpy对象数组,其中包含所有不同的贴合信息对象。的形状 .fit_info 应该与参数数组相同:
>>> fitter.fit_info.shape
(50, 50)
>>> fitter.fit_info.ndim
2
对贴合信息进行索引将返回特定的贴合信息对象,例如
>>> fitter.fit_info[10, 20]
message: The maximum number of function evaluations is exceeded.
success: False
status: 0
fun: [-2.169e-01 -2.398e-01 ... -5.502e-02 2.498e-01]
x: [ 5.352e+02 2.034e+04 3.932e+03]
cost: 0.575174901185717
jac: [[ 3.514e-05 -2.166e-05 9.810e-05]
[ 3.793e-05 -2.329e-05 1.051e-04]
...
[ 1.200e-03 -5.990e-04 2.197e-03]
[ 1.277e-03 -6.343e-04 2.316e-03]]
grad: [-5.634e-06 2.866e-06 -1.092e-05]
optimality: 1.0921480583423703e-05
active_mask: [0 0 0]
nfev: 100
njev: 93
param_cov: [[ 5.965e+08 2.262e+09 2.913e+08]
[ 2.262e+09 8.584e+09 1.106e+09]
[ 2.913e+08 1.106e+09 1.427e+08]]
以返回拟合范围的方式索引拟合信息,例如 fitter.fit_info[10:20, 20:30] ,将返回 FitInfoArrayContainer object.
还可以将所有fit的这些键之一作为数组检索,例如:
>>> nfev = fitter.fit_info.get_property_as_array('nfev')
>>> nfev.shape
(50, 50)
>>> nfev[0:3, 0:3]
array([[ 9, 8, 10],
[10, 13, 9],
[10, 13, 10]])
>>> param_cov = fitter.fit_info.get_property_as_array('param_cov')
>>> param_cov.shape
(50, 50, 3, 3)
诊断#
多次拟合模型的挑战之一是了解问题出现时哪里出了问题。默认情况下,如果拟合失败并出现警告或异常,则该拟合的参数将设置为NaN,并且不会向用户显示任何警告或异常。但是,获得更多信息可能会有所帮助,例如发生的特定错误或异常。
您可以通过设置 diagnostics= 论点这允许您选择是否输出有关以下的信息:
错误的配合失败 (
diagnostics='error'),适合错误或警告 (
diagnostics='error+warn'),或者所有拟合 (
diagnostics='all').
如果 diagnostics 指定了选项,您还需要指定 diagnostics_path ,这应该是包含所有输出的文件夹的路径。每个需要输出的拟合都将被分配一个子文件夹,该子文件夹以沿数据轴(不包括拟合轴)的索引命名。产出将包括(如适用):
error.log,包含发生的任何异常的详细信息warn.log,包含任何警告
您可能还想自动创建配合图、检查正在配合的数据或检查模型。为此,您可以将函数传递给 diagnostics_callable .看到 parallel_fit_dask() 有关此函数应该接受的参数的更多信息。
调度器#
默认情况下, parallel_fit_dask() 将利用 'processes' 调度程序,这意味着可以使用本地机器上的多个进程。方法一起使用的调度程序 scheduler= 关键字参数。您可以将其设置为调度程序的名称(例如 'synchronous' ),或者您可以将其设置为 'default' 为了利用当前活动的daskschedule,例如,它允许您设置 dask.distributed 调度员。